ARCH·GARCH — 분산이 움직이는 시계열의 변동성 모델링
지금까지 살펴본 ARIMA, ETS, Prophet은 모두 평균(mean)을 예측하는 모형입니다. 잔차의 분산이 시간에 따라 일정하다(등분산, homoskedasticity)는 가정이 깔려 있습니다. 그런데 금융 수익률 데이터는 이 가정을 정면으로 위반합니다. 주가가 급락하는 날에는 변동성이 폭발하고, 조용한 시장에서는 변동이 거의 없습니다. 분산 자체가 움직입니다.
이 포스트에서는 이 현상을 직접 모델링하는 ARCH·GARCH 계열을 S&P 500(2010–2024) 실데이터로 분석합니다.
1. 문제 인식 — 변동성 군집화
S&P 500 일별 로그수익률을 시각화하면 두 가지 사실이 드러납니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import numpy as np
import pandas as pd
import yfinance as yf
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf
sp500 = yf.download('^GSPC', start='2010-01-01', end='2024-12-31')['Close'].squeeze()
returns = np.log(sp500 / sp500.shift(1)).dropna() * 100 # 퍼센트 단위
fig, axes = plt.subplots(2, 2, figsize=(12, 7))
axes[0, 0].plot(returns, color="steelblue", linewidth=0.6)
axes[0, 0].set_title("S&P 500 일별 로그수익률 (%)")
axes[0, 1].plot(returns ** 2, color="indianred", linewidth=0.6)
axes[0, 1].set_title("수익률² — 변동성 군집화")
plot_acf(returns, ax=axes[1, 0], lags=40, title="수익률 ACF")
plot_acf(returns ** 2, ax=axes[1, 1], lags=40, title="수익률² ACF")
plt.tight_layout()
plt.show()
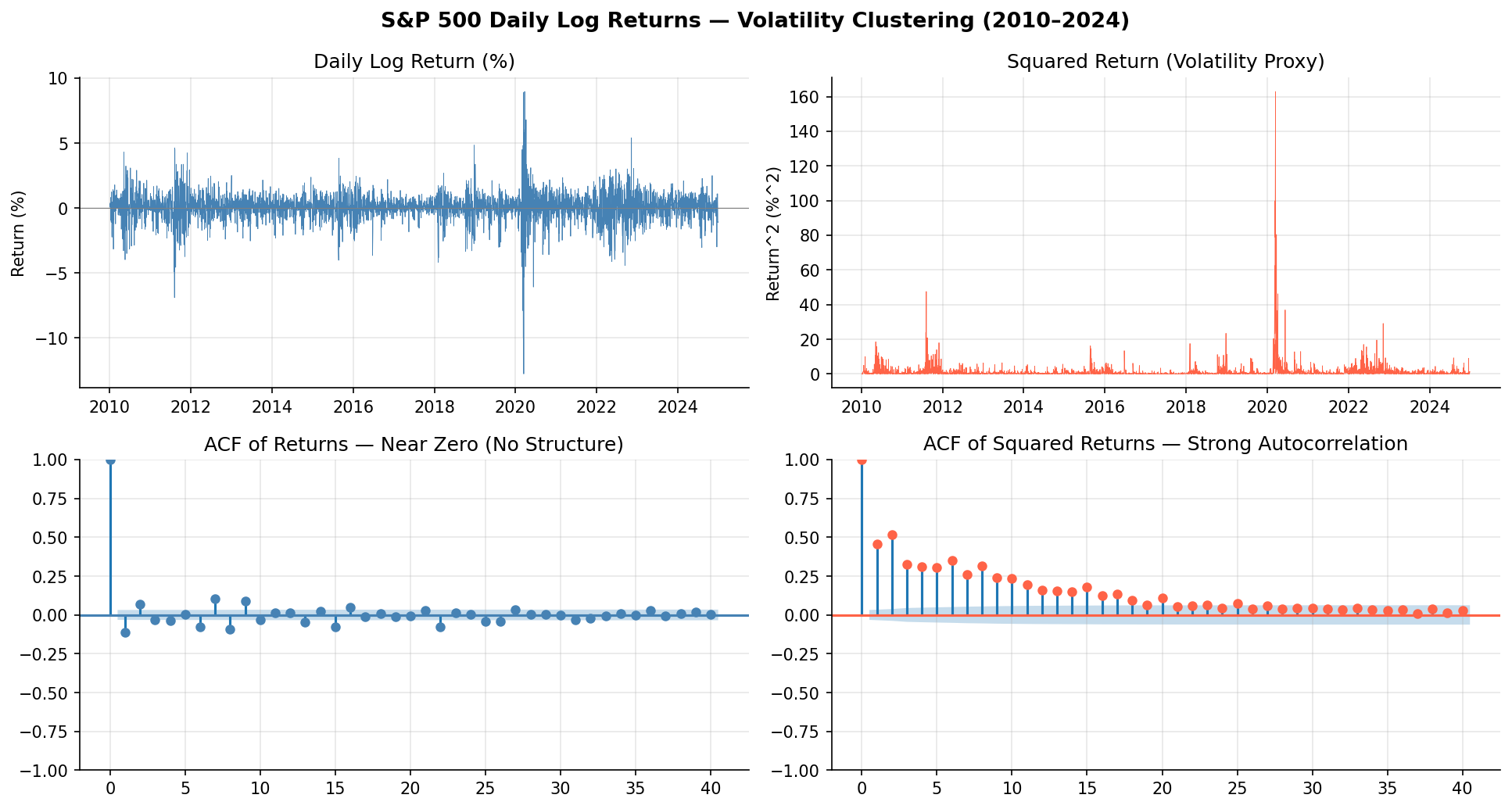
- 수익률 ACF (왼쪽 아래): lag 1부터 거의 0 — 자기상관 없음. ARIMA 관점에서는 “이미 백색잡음”
- 수익률² ACF (오른쪽 아래): lag 40까지 유의한 자기상관이 지속됨
이것이 변동성 군집화(volatility clustering)입니다.
여기서 “군집화”는 공간적으로 점들이 모여 있다는 뜻이 아니라, 시간축에서 비슷한 변동성 상태가 연속적으로 나타난다는 뜻입니다. 수익률의 방향(오를지 내릴지)은 내일을 예측하기 어렵지만, 수익률의 크기(얼마나 크게 움직일지)는 연속성이 있습니다.
- 주가가 오늘 3% 급락했다면 → 내일도 큰 폭으로 움직일 가능성이 높습니다 (올라도 되고 내려도 됩니다, 단지 크게 움직인다는 것)
- 시장이 오늘 0.1% 소폭 변동했다면 → 내일도 조용할 가능성이 높습니다
즉 “큰 변동은 큰 변동끼리, 작은 변동은 작은 변동끼리 시간상 가까운 구간에 몰려 나타난다“는 현상입니다. 차트에서 2020년 COVID 충격 구간을 보면 수익률 제곱이 한꺼번에 폭발하고 이후 서서히 잦아드는 패턴이 뚜렷합니다. 수익률² ACF에서 lag 40까지 자기상관이 남아있다는 것은, 오늘의 변동성이 40 거래일(약 2개월) 이전의 변동성과도 통계적으로 연관된다는 뜻입니다.
ARIMA는 수익률의 방향 구조를 다루는 모형이라 이 분산 구조를 포착할 수 없습니다.
2. ARCH — 조건부 분산의 자기회귀
“조건부(conditional)”가 무슨 뜻인가
통계에서 “조건부”는 “특정 정보를 알고 있다는 전제 하에”라는 뜻입니다. 분산에 적용하면 다음과 같이 구분됩니다:
- 무조건부 분산: 아무 정보 없이 계산한 장기 평균 분산. 전체 데이터를 통틀어 “평균적으로 분산이 얼마다”를 나타내는 고정된 숫자 하나
- 조건부 분산: 어제까지의 수익률과 충격을 알고 있을 때 오늘의 분산. 매일 새로운 정보가 들어올수록 업데이트되어 날마다 달라짐
ARCH·GARCH에서 “어제까지 알고 있는 정보”는 구체적으로 두 가지입니다:
| 참조하는 과거 데이터 | 표기 | 의미 |
|---|---|---|
| 과거 충격(수익률 잔차) 제곱 | $\epsilon_{t-1}^2,\, \epsilon_{t-2}^2, \ldots$ | 어제·그제 시장이 얼마나 크게 흔들렸는가 |
| 과거 조건부 분산 | $\sigma_{t-1}^2,\, \sigma_{t-2}^2, \ldots$ | 어제·그제 모형이 추정한 변동성 수준 |
ARCH는 첫 번째(과거 충격)만, GARCH는 둘 다 씁니다. “분산 자체도 어제 분산에 의존한다”가 GARCH가 ARCH보다 적은 파라미터로 긴 기억을 표현할 수 있는 이유입니다.
Robert Engle이 1982년 제안한 ARCH(Autoregressive Conditional Heteroskedasticity)는 이 아이디어의 출발점입니다.1 수익률 모형을 두 층으로 분리합니다:
\[r_t = \mu + \epsilon_t, \quad \epsilon_t = \sigma_t z_t, \quad z_t \overset{\text{i.i.d.}}{\sim} N(0,1)\]- $\mu$: 조건부 평균
- $\sigma_t$: 조건부 표준편차 — 시간에 따라 변하는 핵심 항
- $z_t$: 표준 백색잡음 (평균 0, 분산 1, 서로 독립)
왜 이 방식이 동작하는가
섹션 1의 ACF 차트에서 $r_t^2$에 자기상관이 있다는 것을 확인했습니다. 이 관찰이 ARCH의 출발점입니다.
$\epsilon_t = \sigma_t z_t$ 이므로 양변을 제곱하면:
\[\epsilon_t^2 = \sigma_t^2 \cdot z_t^2\]$z_t$는 평균 0, 분산 1인 백색잡음이므로 $E[z_t^2] = 1$입니다. 따라서 과거 정보를 알고 있을 때 $\epsilon_t^2$의 기댓값은:
\[E[\epsilon_t^2 \mid \text{과거 정보}] = \sigma_t^2 \cdot E[z_t^2] = \sigma_t^2\]즉, $\epsilon_t^2$의 조건부 기댓값이 곧 $\sigma_t^2$ 입니다. $\sigma_t$ 자체는 직접 관측할 수 없지만, 관측 가능한 $\epsilon_t^2$가 그것의 불편추정량 역할을 합니다.
섹션 1에서 $r_t^2$의 ACF가 자기상관을 보였다는 것은 “$\epsilon_t^2$을 과거 $\epsilon_{t-1}^2, \epsilon_{t-2}^2, \ldots$로 회귀할 수 있다”는 뜻이고, 위 관계에 의해 이것은 곧 “$\sigma_t^2$를 과거 충격 제곱으로 예측할 수 있다”는 뜻이 됩니다. ARCH는 이 회귀를 정확히 수행합니다.
ARCH(q) 조건부 분산:
\[\sigma_t^2 = \omega + \alpha_1 \epsilon_{t-1}^2 + \alpha_2 \epsilon_{t-2}^2 + \cdots + \alpha_q \epsilon_{t-q}^2\]$\omega$는 절편(분산의 기저 수준), $\alpha_i$는 $i$일 전 충격이 오늘 분산에 미치는 가중치입니다. $\alpha_i$가 크면 과거 충격이 오늘 분산에 강하게 반영됩니다.
파라미터 제약: $\omega > 0$, $\alpha_i \geq 0$, $\sum \alpha_i < 1$ (분산의 정상성 조건)
한계: 금융 데이터의 변동성은 오래 지속됩니다. 이를 ARCH로만 포착하려면 $q$가 수십 이상이 되어야 합니다.
3. GARCH — 일반화된 조건부 분산
Tim Bollerslev가 1986년 제안한 GARCH(Generalized ARCH)는 과거 분산 항을 추가해 긴 기억을 적은 파라미터로 표현합니다.2 ARMA가 AR과 MA를 결합해 고차 AR을 단순화하는 것과 같은 논리입니다.
GARCH(p, q) 조건부 분산:
\[\sigma_t^2 = \omega + \sum_{i=1}^{q} \alpha_i \epsilon_{t-i}^2 + \sum_{j=1}^{p} \beta_j \sigma_{t-j}^2\]| 항 | 이름 | 역할 |
|---|---|---|
| $\omega$ | 장기 분산 기저 | 분산이 회귀하는 무조건 평균 수준 |
| $\alpha_i \epsilon_{t-i}^2$ | ARCH 항 | 과거 충격(뉴스 효과)에 대한 단기 반응 |
| $\beta_j \sigma_{t-j}^2$ | GARCH 항 | 과거 분산의 지속성 |
실전에서는 파라미터 수가 가장 적은 GARCH(1,1)부터 시작합니다. 더 복잡한 확장 모형이 필요한지는 MLE로 구한 AIC로 비교합니다(5절 참고):
\[\sigma_t^2 = \omega + \alpha \epsilon_{t-1}^2 + \beta \sigma_{t-1}^2\]주요 파라미터 해석:
- $\alpha + \beta$: 변동성 지속성(persistence). 1에 가까울수록 충격이 오래 지속됨
- 무조건 분산(long-run variance): $\bar{\sigma}^2 = \omega / (1 - \alpha - \beta)$
- 정상성 조건: $\alpha + \beta < 1$
4. GARCH 확장 — 레버리지 효과
GARCH(1,1)은 상승과 하락 충격을 대칭으로 취급합니다. 실제 주식시장에서는 하락 충격이 상승 충격보다 변동성을 더 크게 키우는 비대칭성이 관찰됩니다. 주가 하락 → 기업 레버리지 비율 상승 → 주식 위험 증가로 이어지는 경로가 알려져 있어 레버리지 효과(leverage effect)라 부릅니다.
GJR-GARCH
비대칭 효과를 지시변수 하나로 단순하게 표현합니다:
\[\sigma_t^2 = \omega + \alpha \epsilon_{t-1}^2 + \gamma \epsilon_{t-1}^2 \mathbf{1}[\epsilon_{t-1} < 0] + \beta \sigma_{t-1}^2\]$\gamma > 0$이면 음의 충격($\epsilon_{t-1} < 0$, 즉 하락)에 대해 분산이 $\alpha + \gamma$만큼 반응 — 상승 시의 $\alpha$보다 크게 반응합니다.
EGARCH (Exponential GARCH)
Nelson(1991)이 제안.3 로그 분산을 모델링해 파라미터 비음수 제약이 자동 충족되고 충격의 부호를 구분합니다:
\[\log \sigma_t^2 = \omega + \sum_{j} \beta_j \log \sigma_{t-j}^2 + \sum_{i} \left[ \alpha_i z_{t-i} + \gamma_i \left(|z_{t-i}| - \sqrt{2/\pi}\right) \right]\]$\gamma_i < 0$이면 레버리지 효과 포착.
| 모형 | 레버리지 | 파라미터 제약 |
|---|---|---|
| ARCH(q) | ❌ | $\alpha_i \geq 0$ |
| GARCH(p,q) | ❌ | $\alpha, \beta \geq 0$ |
| GJR-GARCH | ✅ | $\alpha, \beta \geq 0,\; \alpha+\gamma \geq 0$ |
| EGARCH | ✅ | 없음 (log scale) |
5. 추정과 실분석
GARCH의 파라미터(ω, α, β)는 최대가능도추정(MLE)으로 구합니다(가능도 개념). 수익률 잔차는 정규분포보다 꼬리가 두꺼운 경우가 많아 t-분포를 오차 분포로 씁니다. MLE로 구한 로그가능도는 모형 복잡도를 보정한 AIC로 변환해 어느 모형이 더 나은지 비교합니다.
S&P 500 — GARCH(1,1) vs GJR-GARCH(1,1)
1
2
3
4
5
6
7
8
9
10
11
from arch import arch_model
# GARCH(1,1) — t-분포 오차
res_garch = arch_model(returns, vol='GARCH', p=1, q=1, dist='t').fit(disp='off')
# GJR-GARCH(1,1) — t-분포 오차 (o=1이 gamma 항)
res_gjr = arch_model(returns, vol='GARCH', p=1, o=1, q=1, dist='t').fit(disp='off')
# AIC 비교 — 낮을수록 좋음
print(f"GARCH(1,1) AIC: {res_garch.aic:.1f}")
print(f"GJR-GARCH(1,1) AIC: {res_gjr.aic:.1f}")
S&P 500(2010–2024) 기준 결과: GARCH(1,1) AIC ≈ 20 134, GJR-GARCH AIC ≈ 20 088. GJR이 AIC 기준으로 더 낫고, 아래 파라미터 추정치에서 레버리지 효과($\gamma = 0.29$)가 통계적으로 유의해 이 데이터에서는 GJR을 선택합니다. 레버리지 효과가 약하거나 데이터가 짧은 경우 GARCH(1,1)으로도 충분할 수 있습니다.
GJR-GARCH(1,1) 추정 결과 (2010–2024, 3,772일):
| 파라미터 | 값 | 의미 |
|---|---|---|
| $\mu$ | 0.0667 | 일평균 수익률 0.067% |
| $\omega$ | 0.0289 | 장기 분산 기저 |
| $\alpha$ | 0.0000 | 상승 충격의 즉각 반응 |
| $\gamma$ | 0.2895 | 레버리지 효과 크기 |
| $\beta$ | 0.8321 | 변동성 지속성 |
| $\nu$ (자유도) | 5.75 | t-분포 두꺼운 꼬리 |
$\alpha = 0$이고 $\gamma = 0.29$라는 결과가 인상적입니다. 상승 충격은 변동성에 즉각 영향을 주지 않지만, 하락 충격은 다음 날 분산을 29% 포인트 추가로 키웁니다. S&P 500의 비대칭성이 선명합니다.
지속성은 $\alpha + \beta = 0.83$으로, GARCH(1,1)의 0.99보다 훨씬 낮습니다. GJR에서는 충격 효과의 상당 부분이 $\gamma$(비대칭 항)로 분리되기 때문입니다.
장기 무조건 표준편차는 $\bar{\sigma} \approx 1.12\%$/일입니다. 앞서 설명한 “무조건부 분산” — 아무 정보 없이 계산한 장기 평균 분산 — 의 제곱근으로, $\bar{\sigma} = \sqrt{\omega / (1 - \alpha - \gamma/2 - \beta)}$로 계산합니다. 연환산하면 $1.12\% \times \sqrt{252} \approx 17.8\%$로, S&P 500의 장기 평균 연간 변동성과 일치합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 두 모형의 조건부 변동성 (조건부 표준편차)
vol_garch = res_garch.conditional_volatility
vol_gjr = res_gjr.conditional_volatility
fig, axes = plt.subplots(3, 1, figsize=(12, 9), sharex=True)
# (상단) 수익률 + 이벤트 마커
axes[0].plot(returns, color="lightgray", linewidth=0.6)
for date, label in [("2011-08-05", "신용등급 강등"), ("2020-03-16", "COVID 충격")]:
axes[0].axvline(pd.Timestamp(date), color="crimson", linestyle="--", linewidth=1)
axes[0].set_title("S&P 500 수익률과 주요 이벤트")
# (중단) 두 모형의 조건부 변동성
axes[1].plot(vol_garch, label="GARCH(1,1)", linewidth=0.9)
axes[1].plot(vol_gjr, label="GJR-GARCH(1,1)", linewidth=0.9)
axes[1].set_title("조건부 변동성 비교")
axes[1].legend()
# (하단) 두 모형의 차이
axes[2].plot(vol_gjr - vol_garch, color="purple", linewidth=0.7)
axes[2].axhline(0, color="k", linewidth=0.5)
axes[2].set_title("GJR − GARCH (레버리지 효과)")
plt.tight_layout()
plt.show()
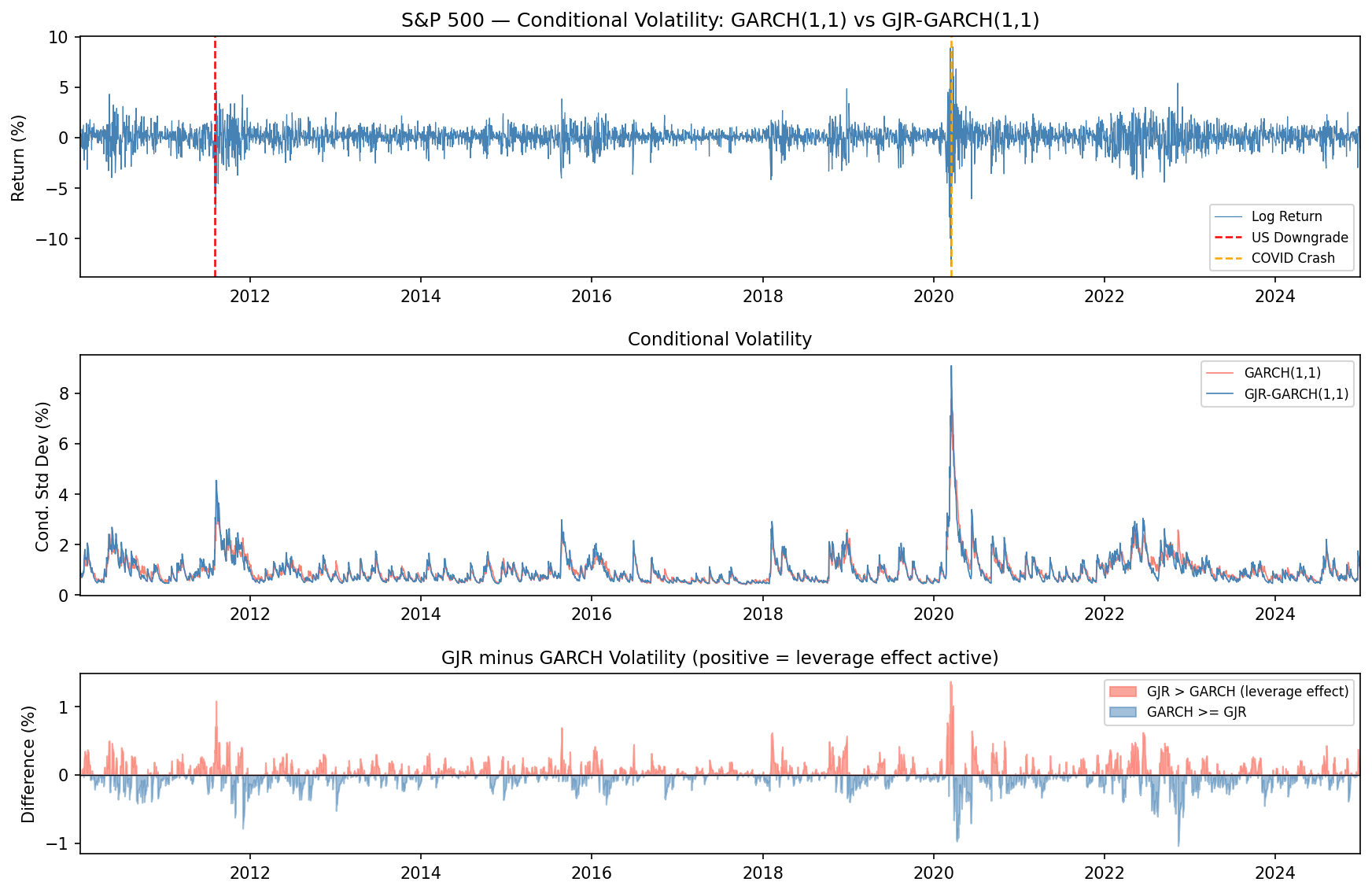
상단: S&P 500 수익률과 두 이벤트 마커(2011년 미국 신용등급 강등, 2020년 COVID 충격). 중단: GARCH(1,1)과 GJR-GARCH(1,1)의 조건부 변동성 — COVID 구간에서 변동성이 8% 이상으로 치솟고 이후 빠르게 수렴합니다. 하단: 두 모형의 차이 — 하락 충격이 집중된 시점(음의 수익률이 큰 날)에 GJR이 GARCH보다 일관되게 높은 변동성을 추정합니다. 레버리지 효과가 실재함을 시각적으로 확인할 수 있습니다.
6. 진단
진단 절차:
적합 후 표준화 잔차 $\hat{z}_t = \hat{\epsilon}_t / \hat{\sigma}_t$를 검토합니다. GARCH가 분산 구조를 충분히 잡았다면 $\hat{z}_t$와 $\hat{z}_t^2$ 모두 백색잡음이어야 합니다.
1
2
3
4
5
6
7
8
9
10
11
std_resid = res_gjr.std_resid
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes[0, 0].plot(std_resid, color="steelblue", linewidth=0.6)
axes[0, 0].set_title("표준화 잔차 $\\hat{z}_t$")
axes[0, 1].plot(std_resid ** 2, color="indianred", linewidth=0.6)
axes[0, 1].set_title("표준화 잔차² $\\hat{z}_t^2$")
plot_acf(std_resid, ax=axes[1, 0], lags=40, title="$\\hat{z}_t$ ACF")
plot_acf(std_resid ** 2, ax=axes[1, 1], lags=40, title="$\\hat{z}_t^2$ ACF")
plt.tight_layout()
plt.show()
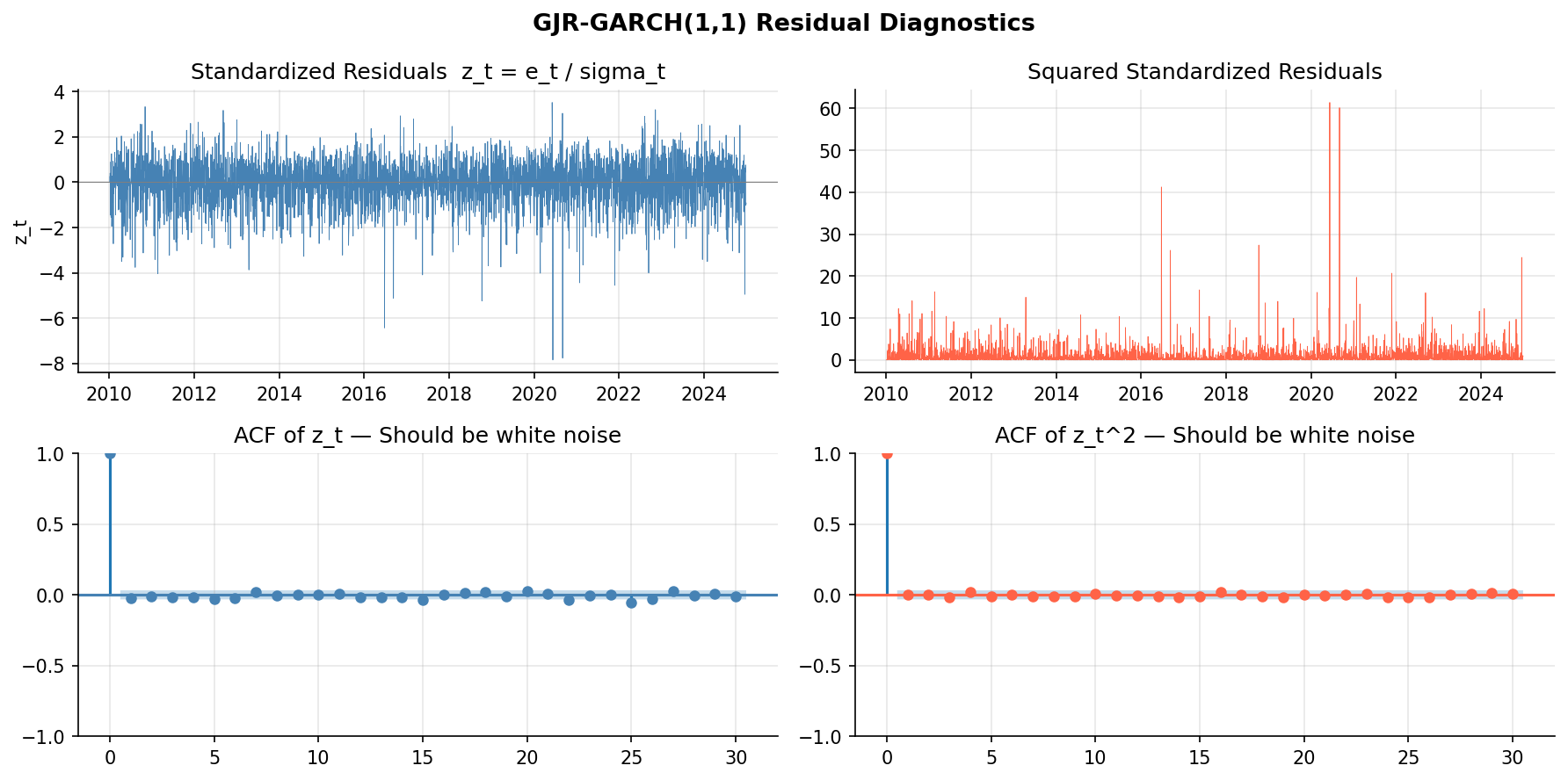
상단 좌: 표준화 잔차 $\hat{z}_t$ 시계열. 대체로 ±3 안에 머물지만 2020년 COVID 충격 구간에서 −8 수준의 극단값이 남아 있습니다. t-분포로도 완전히 포착되지 않는 꼬리 위험이 존재한다는 뜻입니다.
상단 우: 표준화 잔차 제곱 $\hat{z}_t^2$. COVID 구간의 극단값이 더 눈에 띕니다.
하단 좌: $\hat{z}_t$ ACF — 모든 lag에서 신뢰구간 안. 평균 구조가 잘 포착됐음을 의미합니다.
하단 우: $\hat{z}_t^2$ ACF — 마찬가지로 신뢰구간 안. 분산 구조(변동성 군집화)도 GJR-GARCH(1,1)이 충분히 흡수했다는 뜻입니다.
두 ACF 모두 백색잡음이면 모형이 평균·분산 구조를 모두 잡은 것으로 판단합니다.
7. 변동성 예측과 VaR
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 향후 10 거래일 예측
forecasts = res_gjr.forecast(horizon=10, reindex=False)
fcast_vol = np.sqrt(forecasts.variance.values[-1]) # 조건부 표준편차
fcast_mean = forecasts.mean.values[-1] # 조건부 평균
# 1일 VaR (Value at Risk, 최대예상손실; 정규 근사)
var95 = -(fcast_mean - 1.645 * fcast_vol)
var99 = -(fcast_mean - 2.326 * fcast_vol)
# 시각화 — 최근 80일 변동성 + 10일 예측, 예측 구간 VaR
recent_vol = res_gjr.conditional_volatility[-80:]
future_idx = range(len(recent_vol), len(recent_vol) + 10)
fig, axes = plt.subplots(2, 1, figsize=(12, 7))
axes[0].plot(range(len(recent_vol)), recent_vol, color="steelblue", label="조건부 변동성")
axes[0].plot(future_idx, fcast_vol, "r--", marker="o", label="10일 예측")
axes[0].axhline(1.12, color="gray", linestyle=":", label="장기 평균 ≈1.12%")
axes[0].set_title("조건부 변동성과 10일 예측")
axes[0].legend()
axes[1].plot(future_idx, var95, marker="o", label="VaR 95%")
axes[1].plot(future_idx, var99, marker="s", label="VaR 99%")
axes[1].set_title("예측 기간 1일 VaR (%)")
axes[1].legend()
plt.tight_layout()
plt.show()
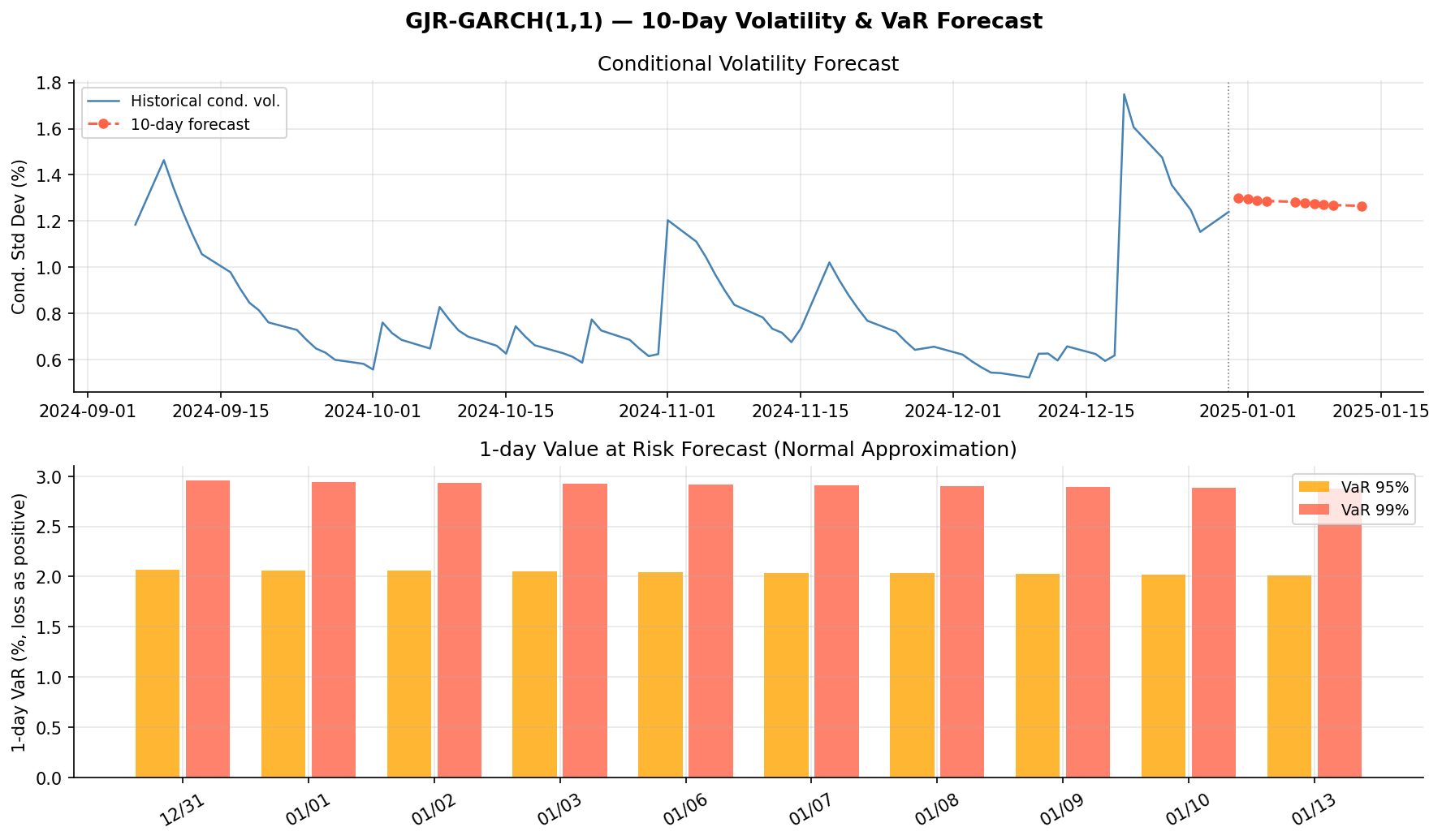
상단: 2024년 말 기준 최근 80 거래일 조건부 변동성(파란 실선)과 향후 10일 예측(빨간 점선). 변동성이 소폭 상승한 상태에서 장기 평균(≈1.12%)으로 점차 수렴하는 모습입니다. 하단: 예측 기간의 1일 VaR(Value at Risk, 최대예상손실) — VaR 95%는 약 2.1%, VaR 99%는 약 3.0%. “95% 신뢰수준에서 하루 손실이 2.1%를 넘지 않을 것”으로 해석합니다.
VaR는 주어진 신뢰수준에서 특정 기간 동안 발생할 수 있는 손실의 경계값입니다. 즉 “얼마나 자주”가 아니라 “어디까지 손실을 감수해야 하는가”를 숫자로 요약한 리스크 지표입니다. 실무에서는 거래 포지션 한도 설정, 자기자본 대비 위험 관리, 스트레스 구간에서의 손실 규모 점검에 널리 사용됩니다.
VaR 해석 주의사항: 여기서 사용한 정규 근사 VaR는 보수적이지 않을 수 있습니다. t-분포 분위수를 직접 사용하거나 MCMC로 사후 분포 전체를 활용하면 꼬리 위험을 더 정확히 추정할 수 있습니다.
8. GARCH의 위치 — 무엇을 예측하는가
GARCH는 수익률의 방향(평균)을 예측하지 않습니다. 분산(변동성)을 예측합니다.
| 활용 | 내용 |
|---|---|
| VaR / CVaR | 분포의 하위 꼬리 추정 — 리스크 한도 설정 |
| 옵션 가격 결정 | 내재 변동성의 시계열 모형으로 활용 |
| 포트폴리오 최적화 | 시변 공분산 행렬 추정 (DCC-GARCH 등) |
| 거래 신호 | 변동성 급등 구간 사전 포착 |
평균 예측이 목적이라면 수익률 평균 구조를 ARIMA로, 잔차 분산을 GARCH로 동시에 모델링하는 ARIMA-GARCH 결합 모형이 실전에서 더 일반적입니다.
9. 한계
| 한계 | 설명 |
|---|---|
| 평균 예측 불가 | 변동성만 예측. 방향은 알 수 없음 |
| 단변량 | 자산 간 변동성 공전이 미처리. 다변량은 DCC-GARCH, BEKK 등 필요 |
| 분포 가정 민감성 | 극단적 꼬리(블랙스완)는 t-분포로도 과소추정될 수 있음 |
| 구조 변화 미처리 | 금융위기처럼 체제 자체가 바뀌는 상황은 Markov-Switching GARCH 등 필요 |
지금까지의 시계열 포스트 흐름을 정리하면: ARIMA는 평균 구조의 자기상관을, ETS는 지수가중 분해를, Prophet은 회귀 분해를 다뤘습니다. GARCH는 이들이 모두 가정했던 등분산 조건을 내려놓고, 분산 자체를 시계열로 모델링합니다. 금융 데이터에서는 방향보다 변동성이 더 예측 가능한 경우가 많기 때문에, GARCH는 리스크 관리의 실질적 표준 도구입니다.
참고문헌
- Engle, R. F. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica, 50(4), 987–1007.
- Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics, 31(3), 307–327.
- Nelson, D. B. (1991). Conditional heteroskedasticity in asset returns: A new approach. Econometrica, 59(2), 347–370.
- Tsay, R. S. (2010). Analysis of Financial Time Series (3rd ed.). Wiley.
AI의 도움을 받아 작성되었으며 최대한 레퍼런스를 밝히려 노력했으나 오류가 있을 수 있으니 정확한 정보를 다시 한번 확인하시기 바랍니다.
Engle, R. F. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica, 50(4), 987–1007. ↩︎
Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics, 31(3), 307–327. ↩︎
Nelson, D. B. (1991). Conditional heteroskedasticity in asset returns: A new approach. Econometrica, 59(2), 347–370. ↩︎