지수평활부터 ETS까지 — 단변량 시계열의 또 다른 표준
지난 시리즈에서 ARIMA/SARIMA를 끝까지 다뤘습니다. 시계열 분야에는 ARIMA와 거의 맞먹는 또 다른 표준 모형군이 있습니다. 지수평활(Exponential Smoothing) 과 그 정점인 ETS입니다. Hyndman & Athanasopoulos(2021)의 Forecasting: Principles and Practice에서도 ARIMA보다 앞 챕터에서 다뤄집니다.
SES에서 시작해서 추세, 계절성을 차례로 더해 가며 ETS까지 올라가고, 마지막에 같은 Air Passengers 데이터로 ETS와 SARIMA를 수치 비교합니다.
1. 지수평활의 발상 — “최근 값을 더 무겁게”
$y_1, y_2, \ldots, y_t$가 주어졌을 때 $\hat{y}_{t+1}$을 어떻게 예측할까요.
가장 단순한 두 가지 선택지:
- (전체 평균) $\hat{y}_{t+1} = \bar{y} = \frac{1}{t} \sum_{i=1}^{t} y_i$
- (직전 값) $\hat{y}_{t+1} = y_t$
전체 평균은 모든 과거를 똑같이 취급해 너무 둔감하고, 직전 값만 쓰는 건 노이즈에 너무 민감합니다. 그 사이의 절충이 이동평균입니다.
\[\hat{y}_{t+1} = \frac{1}{k} \sum_{i=t-k+1}^{t} y_i \quad (\text{윈도우 크기 } k)\]나쁘지 않지만 어색한 부분이 하나 있습니다. 윈도우 안의 값들을 모두 동등하게 취급한다는 것입니다. 어제 값과 일주일 전 값을 같은 무게로 쓰는 게 맞는 선택인지는 생각해볼 여지가 있습니다.
지수평활은 이 부분에 정면으로 답합니다. 최근 값에 더 큰 가중치, 과거로 갈수록 기하급수적으로 줄어드는 가중치를 부여합니다.
\[\hat{y}_{t+1} = \alpha y_t + \alpha(1-\alpha) y_{t-1} + \alpha(1-\alpha)^2 y_{t-2} + \cdots\]가중치 비율 $\alpha, \alpha(1-\alpha), \alpha(1-\alpha)^2, \ldots$는 1, $(1-\alpha)$, $(1-\alpha)^2, \ldots$의 등비수열입니다. 무한 과거를 가정하거나 초기화 효과를 무시하면 모두 합해 1이 되므로 수학적으로 깔끔한 가중평균입니다.
이동평균과 지수평활을 같은 데이터에 적용해 보면:
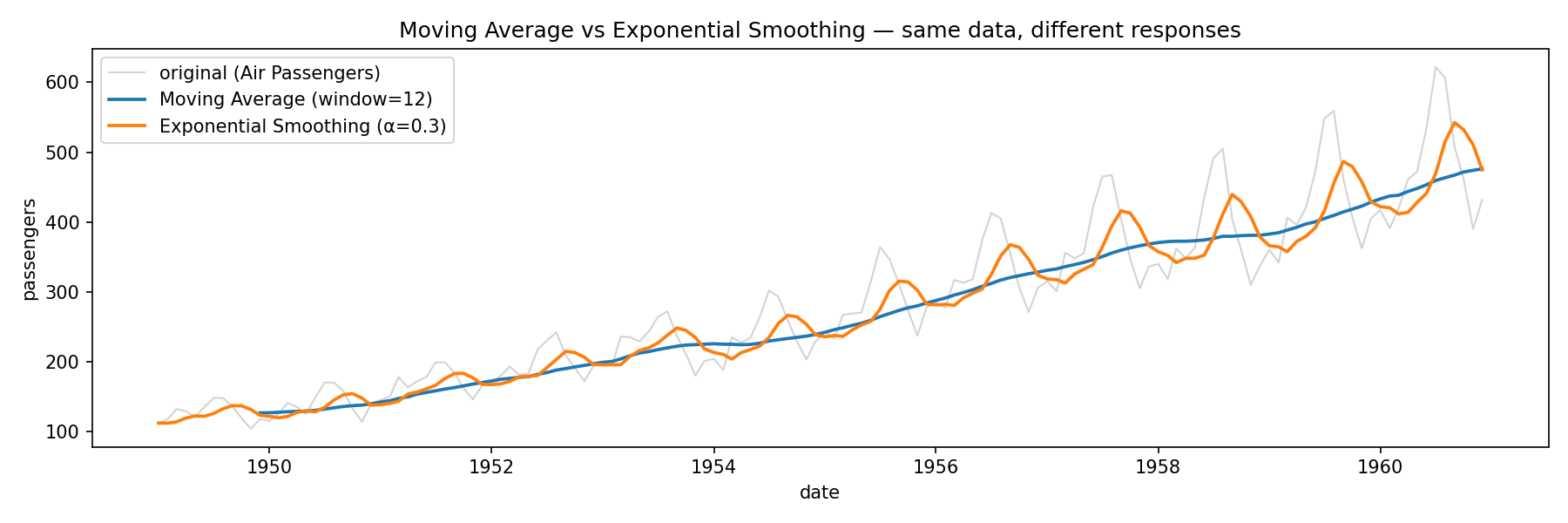
두 곡선이 비슷해 보이지만 미묘한 차이가 있습니다. 이동평균은 윈도우의 양 끝에서 한 점이 들어오거나 빠지면서 약간의 출렁임이 있고, 지수평활은 더 부드럽게 이어집니다. 또 이동평균은 윈도우 크기만큼 시작 부분에서 결측이 생기는 반면, 지수평활은 첫 시점부터 값을 줍니다.
statsmodels 내장 Air Passengers 데이터로 두 방법을 직접 비교해 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.tsa.holtwinters import SimpleExpSmoothing
# Air Passengers 로드 (statsmodels 내장)
ap = sm.datasets.get_rdataset("AirPassengers", "datasets").data
series = pd.Series(
ap["value"].values,
index=pd.date_range("1949-01", periods=144, freq="MS"),
name="passengers",
)
# 이동평균 — 윈도우 k=12 (월별 데이터 기준 1년)
ma = series.rolling(window=12).mean()
# 지수평활 — α=0.3 고정 (smoothing 효과를 눈으로 확인하기 위한 값)
ses = SimpleExpSmoothing(series).fit(smoothing_level=0.3, optimized=False)
fig, ax = plt.subplots(figsize=(12, 4))
ax.plot(series, color="lightgray", label="원본")
ax.plot(ma, label="이동평균 (k=12)", linewidth=1.8)
ax.plot(ses.fittedvalues, label="지수평활 (α=0.3)", linewidth=1.8)
ax.legend()
ax.set_title("이동평균 vs 지수평활 (Air Passengers)")
plt.tight_layout()
plt.show()
플롯에서 보이는 차이는 사실 이 세 가지에서 비롯합니다.
| 이동평균 (k=12) | 지수평활 | |
|---|---|---|
| 시작 시점 | 처음 11개 값은 NaN | 첫 시점부터 값 있음 |
| 가중치 | 윈도우 내 모두 동일 ($\frac{1}{k}$) | 최근일수록 지수적으로 큼 |
| 곡선 모양 | 한 점이 들어오고 빠질 때 미세 출렁임 | 연속적으로 부드럽게 감쇠 |
용어 혼동 — 단순 이동평균과 ARIMA MA
둘 다 선형 필터라는 공통점이 있지만 적용 대상과 해석이 다릅니다.
- 단순 이동평균 (
rolling(k).mean()) → 관측값에 적용 (데이터 평활)- ARIMA MA(q) → 백색잡음 충격에 적용 (모형 구조)
연결 고리는 Slutsky(1927)입니다. 백색잡음 수열 $\varepsilon_t$에 단순 이동평균을 그대로 적용하면:
\[y_t = \frac{1}{k}(\varepsilon_t + \varepsilon_{t-1} + \cdots + \varepsilon_{t-k+1})\]이게 이미 MA 프로세스입니다. Slutsky는 이렇게 만든 수열에서 뚜렷한 주기성이 나타난다는 걸 보였고, 이로부터 “관측된 시계열은 과거 충격들의 누적 효과일 수 있다”는 아이디어가 나왔습니다. ARIMA MA는 여기서 고정된 $\frac{1}{k}$를 자유 파라미터 $\theta_i$로 일반화한 것입니다:
\[y_t = \varepsilon_t + \theta_1\varepsilon_{t-1} + \cdots + \theta_q\varepsilon_{t-q}\]이름이 같은 건 우연이 아닙니다. 다만 관측값 평활로서의 이동평균과 확률과정 생성 모형으로서의 MA(q)를 같은 것으로 받아들이면 안 됩니다. 공통점은 선형 필터이고, 차이는 무엇에 필터를 적용하느냐입니다.
2. SES — 단순지수평활(Simple Exponential Smoothing)
위의 무한합을 매번 계산할 필요는 없습니다. 재귀 형태로 간단히 표현됩니다.
\[\hat{y}_{t+1} = \alpha y_t + (1-\alpha) \hat{y}_t\]이 한 줄이 SES의 전부입니다. 새 예측값은 (이번 관측값과 직전 예측값의 가중평균). $\alpha$는 평활 모수(smoothing parameter)이고 $0 < \alpha < 1$ 범위입니다.1
$\alpha$ 값별로 결과가 꽤 다릅니다.

- $\alpha = 0.1$ (위): 새 관측에 거의 반응 안 함. 매우 부드럽지만 변화에 늦게 따라감.
- $\alpha = 0.5$ (중간): 균형 잡힘.
- $\alpha = 0.9$ (아래): 거의 노이즈를 그대로 따라감. 평활 효과가 거의 없음.
함정 박스 1 — α는 어떻게 정하는가
실무에서 $\alpha$는 보통 데이터로부터 추정합니다. 학습 구간의 잔차 제곱합을 최소화하는 $\alpha$를 찾는 식입니다. statsmodels의
SimpleExpSmoothing(...).fit()이 자동으로 이 일을 해 줍니다. 수동 지정도 가능하지만, 추정 결과가 보통 더 좋습니다.
statsmodels로 적용하면 한 줄입니다.
1
2
3
4
from statsmodels.tsa.holtwinters import SimpleExpSmoothing
model = SimpleExpSmoothing(series).fit() # α 자동 추정
forecast = model.forecast(steps=12)
여기서 한계가 보입니다. SES의 예측은 한 시점 이후로는 모두 같은 값(평탄선) 입니다. $\hat{y}_{t+1} = \hat{y}_{t+2} = \hat{y}_{t+3} = \cdots$. SES는 본질적으로 “수준(level)”만 추적하기 때문에 추세를 모릅니다. 그래서 다음 단계가 필요합니다.
3. Holt’s Linear Trend — 추세 추가
추세가 있는 시계열을 다루려면 수준 외에 기울기도 추적해야 합니다. Holt(1957)가 제안한 방식이 SES에 추세 컴포넌트를 더하는 것입니다.2
\[\begin{aligned} \ell_t &= \alpha y_t + (1-\alpha)(\ell_{t-1} + b_{t-1}) \\ b_t &= \beta(\ell_t - \ell_{t-1}) + (1-\beta) b_{t-1} \\ \hat{y}_{t+h} &= \ell_t + h \cdot b_t \end{aligned}\]세 식의 의미는:
- $\ell_t$: 시점 $t$의 수준(level) — “현재 값이 얼마인가”
- $b_t$: 시점 $t$의 추세 기울기(slope) — “단위 시간당 얼마나 변하는가”. 업데이트 식 $b_t = \beta(\ell_t - \ell_{t-1}) + (1-\beta)b_{t-1}$을 보면, $\ell_t - \ell_{t-1}$이 이번 기에 관측된 수준 변화량(기울기 추정치)이고 이를 이전 기울기와 평활한 값이 $b_t$입니다.
- $h$: 예측 지평(forecast horizon) — 지금 시점 $t$에서 몇 발자국 앞을 예측할지. $h=1$이면 1기 후, $h=12$면 12기 후. SES에 $h$가 없는 이유는 SES 예측 $\hat{y}_{t+h} = \ell_t$가 $h$와 무관하게 항상 같은 값이기 때문입니다.
- $\hat{y}_{t+h} = \ell_t + h \cdot b_t$: 현재 수준에서 기울기 $b_t$로 $h$발자국 직선 외삽
레벨 식에서 눈에 띄는 부분은 $(1-\alpha)$ 항이 $\ell_{t-1}$이 아닌 $\ell_{t-1} + b_{t-1}$이라는 점입니다. $\ell_{t-1} + b_{t-1}$은 직전 시점에서 $y_t$를 예측한 값 $\hat{y}_{t \mid t-1}$입니다. 따라서 레벨 업데이트는 “실제 관측값”과 “한 시점 전에 예측했던 값”을 $\alpha : (1-\alpha)$로 섞는 구조입니다.
| $(1-\alpha)$ 항 | 의미 | |
|---|---|---|
| SES | $\ell_{t-1}$ | 제자리에 있겠지 |
| Holt’s | $\ell_{t-1} + b_{t-1}$ | 추세만큼 올라가 있겠지 |
SES처럼 $(1-\alpha)\ell_{t-1}$만 쓰면 추세가 있는 데이터에서 prior expectation이 항상 실제보다 낮아 레벨 추정이 관측값을 뒤쫓아가는 lag가 생깁니다. $b_{t-1}$을 더해 prior를 추세만큼 앞당김으로써 그 lag를 없앱니다.
예시: $\ell_t = 300$, $b_t = 10$ (월 평균 10단위 증가 추세)일 때
$h$ 예측값 의미 1 310 1개월 후 3 330 3개월 후 12 420 12개월 후 SES였다면 셋 다 300. Holt는 추세를 알기 때문에 $h$가 커질수록 예측값이 선형으로 달라집니다.
평활 모수가 두 개($\alpha, \beta$)로 늘었습니다. $\alpha$는 수준의 평활 정도, $\beta$는 추세의 평활 정도입니다. 둘 다 데이터로부터 추정합니다.
이렇게 하면 SES와 달리 예측값이 평탄하지 않고 선형으로 외삽됩니다.
4. Holt-Winters — 계절성 추가
계절성까지 다루려면 컴포넌트를 하나 더 추가합니다. Holt(1957)와 Winters(1960)의 결합이라 Holt-Winters 또는 삼중지수평활(triple exponential smoothing) 로 불립니다.3
가법 계절성 버전:
\[\begin{aligned} \ell_t &= \alpha (y_t - s_{t-m}) + (1-\alpha)(\ell_{t-1} + b_{t-1}) \\ b_t &= \beta(\ell_t - \ell_{t-1}) + (1-\beta) b_{t-1} \\ s_t &= \gamma (y_t - \ell_t) + (1-\gamma) s_{t-m} \\ \hat{y}_{t+h} &= \ell_t + h \cdot b_t + s_{t+h-m} \end{aligned}\]세 평활 모수($\alpha, \beta, \gamma$)와 한 개의 구조 모수($m$, 계절 주기)가 들어갑니다. 수준, 추세, 계절성 세 컴포넌트가 각자 자기 평활을 따로 합니다.
Holt's Linear Trend
$$ \begin{aligned} \ell_t &= \alpha y_t + (1-\alpha)(\ell_{t-1} + b_{t-1}) \\ b_t &= \beta(\ell_t - \ell_{t-1}) + (1-\beta) b_{t-1} \\ \hat{y}_{t+h} &= \ell_t + h \cdot b_t \end{aligned} $$모수: α, β
Holt-Winters (가법 계절성)
$$ \begin{aligned} \ell_t &= \alpha (y_t - s_{t-m}) + (1-\alpha)(\ell_{t-1} + b_{t-1}) \\ b_t &= \beta(\ell_t - \ell_{t-1}) + (1-\beta) b_{t-1} \\ s_t &= \gamma (y_t - \ell_t) + (1-\gamma) s_{t-m} \\ \hat{y}_{t+h} &= \ell_t + h \cdot b_t + s_{t+h-m} \end{aligned} $$모수: α, β, γ, m
곱셈 계절성 버전은 식의 형태만 살짝 다릅니다 (덧셈을 곱셈/나눗셈으로 대체). Air Passengers처럼 계절 변동의 폭이 수준에 비례해 커지는 경우는 곱셈을 씁니다.
statsmodels로 적용하면 이렇게 됩니다.
1
2
3
4
5
6
7
8
9
from statsmodels.tsa.holtwinters import ExponentialSmoothing
model = ExponentialSmoothing(
train,
trend='add', # 'add' | 'mul' | None
seasonal='mul', # 'add' | 'mul' | None
seasonal_periods=12,
).fit()
forecast = model.forecast(steps=24)
이전 글에서 SARIMA로 다뤘던 Air Passengers에 Holt-Winters(가법 추세 + 곱셈 계절성)를 적용해 보면:
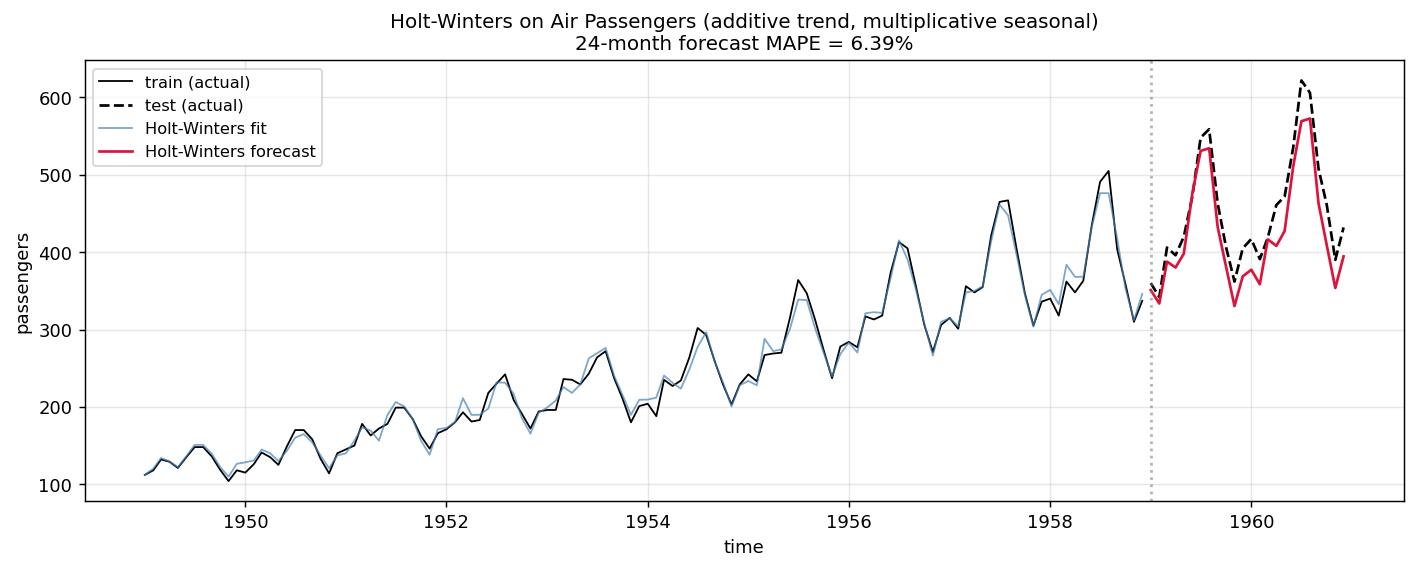
24개월 예측 MAPE가 6.39% 입니다. 이전 글에서 SARIMA(0,1,1)(0,1,1)$_{12}$이 같은 데이터에서 얻은 8.52%보다 살짝 좋습니다. 모형의 가정과 데이터의 성격이 잘 맞으면 Holt-Winters가 SARIMA를 이기는 경우도 흔합니다.
함정 박스 2 — 가법 vs 곱셈 컴포넌트 선택
추세는 보통 가법으로 충분합니다. 헷갈리는 부분은 계절성입니다. 계절 변동의 폭이 시간에 따라 일정하면 가법, 수준에 비례해 커지면 곱셈입니다. Air Passengers는 명확히 곱셈입니다(이전 SARIMA 글에서도 같은 판정). 헷갈리면 두 버전을 다 적합해 보고 잔차의 패턴이 더 깨끗한 쪽을 고르세요.
4.1 그런데 “지수평활”이 정말 예측인가? — 다단계 예측의 모양
한 가지 의문이 남습니다. 이름이 “평활”인데 정말 예측 도구인가? 두 시점 앞을 예측하려면 어떻게 하는가?
핵심을 먼저 짚으면 — 지수평활은 본질적으로 한 발자국 앞 예측(one-step-ahead forecast)을 만드는 재귀 공식입니다. SES의 식 $\hat{y}_{t+1} = \alpha y_t + (1-\alpha)\hat{y}_t$는 “시점 $t$까지의 정보로 $t+1$을 예측한다”는 뜻이지요. 학습 단계에서 시각화되는 부드러운 곡선(fitted values)은 사실 매 시점마다 한 발자국 앞 예측을 모아 놓은 것일 뿐입니다.
문제는 두 발자국 이상 앞 예측입니다. SES 식을 그대로 한 번 더 적용하려고 하면 막힙니다.
\[\hat{y}_{T+2} = \alpha \cdot y_{T+1} + (1-\alpha) \cdot \hat{y}_{T+1}\]여기서 $y_{T+1}$은 아직 관측되지 않은 미래 값이라 모릅니다. 표준적 해법은 $y_{T+1}$ 자리에 그 자체의 예측값 $\hat{y}_{T+1}$을 대입하는 것입니다. 대입하고 정리하면 $\hat{y}_{T+2} = \hat{y}_{T+1}$이 됩니다. 더 일반화하면:
\[\hat{y}_{T+h} = \hat{y}_{T+1} \quad \text{for all } h \geq 1\]SES의 다단계 예측은 모두 같은 값입니다. 이게 본문 2절에서 “SES의 예측은 평탄선”이라고 한 부분의 정확한 수학적 의미입니다. 추세나 계절성 정보가 없으니 더 멀리 갈수록의 모양을 만들어 낼 수 없는 것이죠.
Holt와 Holt-Winters가 컴포넌트를 추가한 이유가 바로 이 한계 때문입니다. 모형별로 $h$ 발자국 앞 예측이 어떻게 다른지 정리하면:
| 모형 | $h$ 발자국 앞 예측 $\hat{y}_{T+h}$ | 멀리 갈수록의 모양 |
|---|---|---|
| SES | $\ell_T$ (상수) | 평탄선 |
| Holt | $\ell_T + h \cdot b_T$ | 직선 (선형 외삽) |
| Holt-Winters | $\ell_T + h \cdot b_T + s_{T+h-m}$ | 추세 + 주기적 계절 패턴 |
마지막 행의 $s_{T+h-m}$이 흥미로운 부분입니다. $h$ 발자국 앞의 계절 컴포넌트는 한 주기($m$) 전의 같은 위치 계절값을 가져다 씁니다. 24개월 예측이라도 계절 주기가 12개월이면 작년 같은 달의 계절 효과를 그대로 다시 사용하는 식이지요. 위 그래프(Holt-Winters on Air Passengers)에서 24개월 예측이 톱니 패턴을 그대로 유지하는 이유가 이것입니다.
함정 박스 3 — 다단계 예측의 예측구간은 시간이 갈수록 넓어진다
다단계 예측은 본질적으로 재귀적입니다. $\hat{y}_{T+1}$의 불확실성이 $\hat{y}_{T+2}$ 계산에 누적되고, 그게 다시 $\hat{y}_{T+3}$에 누적되는 식이지요. 그래서 예측구간이 시간이 갈수록 발산하듯 넓어집니다. 이전 SARIMA 글에서 본 예측구간 발산과 같은 메커니즘입니다. ETS는 상태공간 모형이라 이 누적이 모형 가정 하에서 일관되게 정량화됩니다 —
get_prediction(steps=h).conf_int()로 확인하실 수 있습니다.
이 다단계 예측의 모양 차이가 사실 컴포넌트를 추가한 진짜 이유입니다. 단순히 “더 잘 맞아서”가 아니라, 추세 컴포넌트가 있어야 우상향이 가능하고, 계절 컴포넌트가 있어야 톱니 패턴이 가능하니까요. SES → Holt → Holt-Winters 순서는 결국 “예측 곡선이 취할 수 있는 모양을 하나씩 더 늘리는 과정”입니다.
5. ETS — 상태공간 정식화
여기까지 SES → Holt → Holt-Winters로 컴포넌트를 하나씩 더해 왔습니다. ETS (Error-Trend-Seasonal) 는 이 모든 변형을 하나의 통일된 틀에 담은 것입니다. Hyndman 등이 2002년에 정식화했고4, 현재 시계열 예측의 양대 표준 중 하나입니다.
ETS의 표기는 세 글자입니다.
\[\text{ETS}(\underbrace{\cdot}_{\text{Error}}, \underbrace{\cdot}_{\text{Trend}}, \underbrace{\cdot}_{\text{Seasonal}})\]각 자리에 들어갈 수 있는 값:
| 컴포넌트 | 가능한 값 | 의미 |
|---|---|---|
| Error | A, M | 가법(additive) 또는 곱셈(multiplicative) |
| Trend | N, A, A$_d$ | 없음 / 가법 / 가법 감쇠(damped) |
| Seasonal | N, A, M | 없음 / 가법 / 곱셈 |
위 표를 단순 조합하면 18개 기본 모델군이 됩니다.5 실무에서는 모든 조합이 항상 허용되는 것은 아니므로, 여기서는 대표적인 이름들과의 대응만 보겠습니다.
| ETS 표기 | 별명 |
|---|---|
| ETS(A, N, N) | SES (단순지수평활) |
| ETS(A, A, N) | Holt’s linear trend |
| ETS(A, A, A) | Holt-Winters 가법 |
| ETS(A, A, M) | Holt-Winters 곱셈 |
| ETS(A, A$_d$, A) | 감쇠 추세 + 가법 계절성 |
ETS의 진짜 강점은 상태공간 모형(state space model) 으로 정식화됐다는 점입니다.6 덕분에 기존 Holt-Winters와 비교해 두 가지가 달라집니다.
- 예측구간을 모형 가정 하에서 일관되게 계산할 수 있음 — 기존 Holt-Winters는 점예측만 줄 수 있었지만, ETS는 가능도 기반 예측구간을 줍니다.
- AIC/BIC로 후보 모델 중 자동 선택 가능 — 어떤 컴포넌트 조합이 데이터에 맞는지 정보 기준으로 비교할 수 있습니다.
1
2
3
4
5
6
7
8
from statsmodels.tsa.exponential_smoothing.ets import ETSModel
# 수동 지정
model = ETSModel(train, error='add', trend='add', seasonal='mul',
seasonal_periods=12).fit()
# 또는 R의 forecast::ets()와 statsforecast 패키지의
# AutoETS는 후보 ETS 모델들을 자동 비교해 줍니다.
함정 박스 3 — 여러 ETS 후보 중 어떤 걸 쓰나
자동 선택(R의
forecast::ets()나 Python의statsforecast.AutoETS)이 보통 합리적인 답을 줍니다. 다만 자동 선택이 곱셈 계절성을 고른다면 데이터가 양수여야 합니다 — 음수가 섞인 시계열에서는 가법으로 강제하셔야 합니다. 또 표본 크기가 너무 작으면(2주기 미만) 계절 컴포넌트를 신뢰성 있게 추정할 수 없으니 주기를 잡지 마시기 바랍니다.
6. ETS vs SARIMA — 같은 데이터, 두 가지 접근
이전 글에서 SARIMA(0,1,1)(0,1,1)$_{12}$로 Air Passengers를 24개월 예측했을 때 MAPE 8.52%를 얻었습니다. 같은 train/test split에 ETS(A,A,M)를 적용하면 어떻게 될까요.
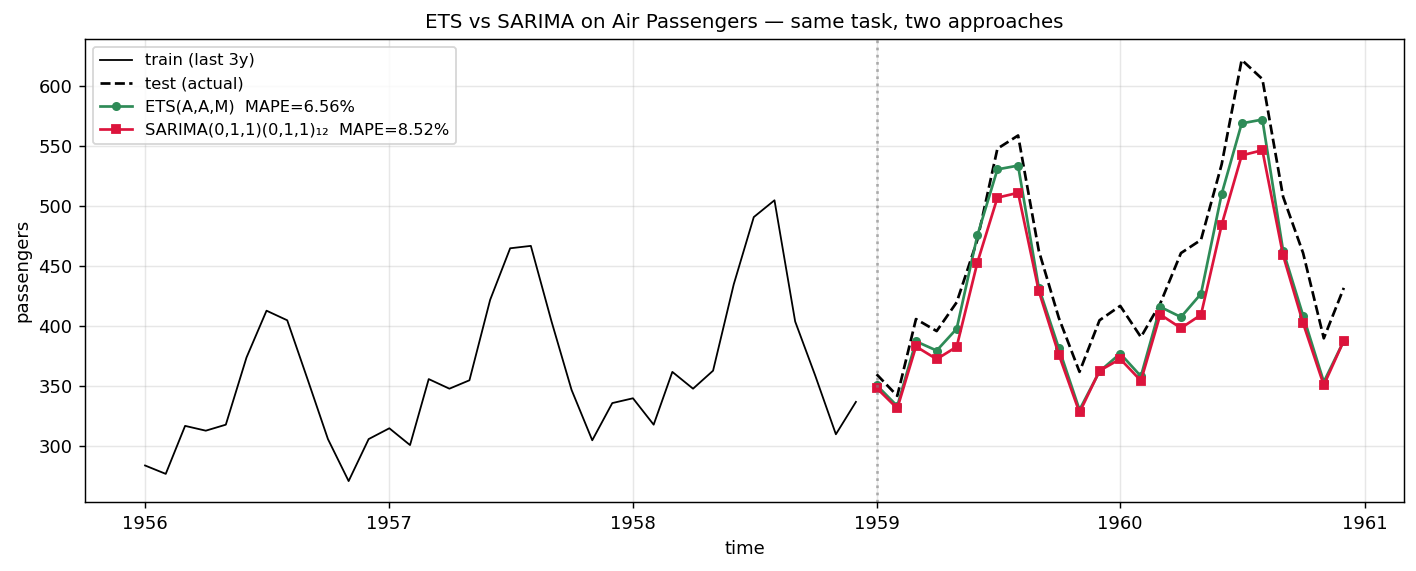
| 모델 | 24개월 예측 MAPE |
|---|---|
| Holt-Winters (수동) | 6.39% |
| ETS(A, A, M) | 6.56% |
| SARIMA(0,1,1)(0,1,1)$_{12}$ | 8.52% |
이 데이터에서는 ETS가 SARIMA보다 살짝 좋습니다. 그렇다고 ETS가 항상 SARIMA보다 좋다는 뜻은 아닙니다. 두 모형은 서로 잘하는 영역이 다릅니다.
| ARIMA / SARIMA | ETS | |
|---|---|---|
| 사고 방식 | “차분 후 정상 시계열의 자기상관” | “수준·추세·계절성을 직접 평활” |
| 잘 다루는 데이터 | 자기상관 구조가 분명한 시계열 | 추세와 계절성이 명확한 시계열 |
| 정상성 가정 | 차분으로 정상화 필요 | 차분 선행 없이 수준·추세·계절성을 직접 추적 |
| 모수 의미 | $\phi, \theta$ (해석 어려움) | $\alpha, \beta, \gamma$ (의미 명확) |
| 자동 선택 | auto_arima (pmdarima) | AutoETS (statsforecast) |
| 여러 시계열에 일괄 적용 | 무거움 | 가벼움 |
6.1 정상성 — ETS가 비정상 시계열에 바로 적용되는 이유
ARIMA는 왜 정상성이 필요한가. ARIMA의 핵심은 자기상관 구조를 추정하는 것입니다. 평균이 이동하는 시계열에서는 자기상관 추정이 의미를 잃기 때문에, 먼저 차분(differencing)으로 평균을 고정합니다. ARIMA의 “I”가 그 차분 횟수입니다.
ETS는 왜 그 과정이 필요 없는가. ETS는 비정상성의 원인(추세, 계절성)을 제거하는 대신 직접 모델링합니다. $\ell_t$는 매 시점 업데이트되어 이동하는 평균을 따라가고, $b_t$ 역시 매 시점 업데이트되어 변화하는 기울기를 추적합니다. “정상화 후 자기상관 분석”이 아니라 “컴포넌트를 직접 추적”하는 패러다임입니다.
흥미로운 사실은 수학적으로는 두 접근이 연결된다는 점입니다.
| ETS | 동치인 ARIMA |
|---|---|
| SES | ARIMA(0,1,1) |
| Holt’s linear | ARIMA(0,2,2) |
일부 선형 additive ETS는 특정 ARIMA와 예측식이 연결됩니다. SES는 일정 조건하에서 1차 차분한 ARIMA(0,1,1)과 같은 예측을 만들고, Holt’s linear도 additive error 등 특정 조건하에서 ARIMA(0,2,2)와 연결됩니다. 내부적으로 비슷한 예측식을 만들 수 있지만, ETS는 그것을 “추세 컴포넌트를 평활한다”는 언어로 표현합니다.7
다만 ETS도 한계는 있습니다. 분산이 수준에 비례해 커지는 경우(Air Passengers처럼)는 곱셈(multiplicative) 버전이 필요하고, 구조적 단절(regime change)은 두 모형 모두 잘 다루지 못합니다.
실무 권고:
- 어떤 게 좋을지 모르겠으면 둘 다 적합해 보고 검증 셋의 성능으로 비교하세요. M3, M4 같은 forecasting 대회에서도 단일 모형이 항상 이기는 일은 없고, 두 모형의 단순 평균이 종종 최고 성능을 보입니다.8
- 자기상관 구조가 복잡한 시계열(거시경제 변수, 금융)은 ARIMA/SARIMA가 강합니다.
- 추세·계절성이 명확하고 자기상관은 단순한 시계열(소매 매출, 트래픽)은 ETS가 강합니다.
- 여러 시계열을 일괄 처리해야 한다면 ETS가 보통 더 가볍고 빠릅니다.
7. 정리 — 무엇을 배웠는가
| 모형 | 추가된 컴포넌트 | 평활 모수 |
|---|---|---|
| SES (지수평활) | 수준 | $\alpha$ |
| Holt | 수준 + 추세 | $\alpha, \beta$ |
| Holt-Winters | 수준 + 추세 + 계절성 | $\alpha, \beta, \gamma$ |
| ETS | 위 모두를 여러 후보 모델로 일반화 + 상태공간 | 동일 + 자동 선택 |
핵심만 추리면:
- 지수평활은 최근 값에 더 큰 가중치를 준다는 단순한 아이디어에서 출발해 컴포넌트를 더해 가며 ETS까지 이어집니다.
- ETS는 ARIMA와 함께 단변량 시계열의 양대 표준입니다. 데이터에 따라 어느 쪽이 나을지가 다릅니다.
- statsforecast의
AutoETS나 R의forecast::ets()는 여러 ETS 후보 중 적절한 것을 자동으로 골라 줍니다.
다음 글에서는 이 미니 시리즈의 2편으로, Prophet의 내부 구조를 들여다보겠습니다. Prophet은 사실 새로운 마법이 아니라 (1) 가법 분해, (2) 푸리에 급수로 계절성, (3) piecewise linear trend, (4) 베이지안 추정 — 이 네 가지의 영리한 조합입니다. 신호처리에 익숙하신 분이면 푸리에 부분에서 친숙한 광경을 보시게 될 것입니다.
참고문헌
- Holt, C. C. (1957). Forecasting seasonals and trends by exponentially weighted moving averages. (ONR Research Memorandum, Carnegie Institute of Technology, 52). Reprinted in International Journal of Forecasting, 20(1), 5–10 (2004).
- Hyndman, R. J., Koehler, A. B., Ord, J. K., & Snyder, R. D. (2008). Forecasting with Exponential Smoothing: The State Space Approach. Springer.
- Hyndman, R. J., & Athanasopoulos, G. (2021). Forecasting: Principles and Practice (3rd ed.). OTexts. https://otexts.com/fpp3/
- Makridakis, S., & Hibon, M. (2000). The M3-Competition: results, conclusions and implications. International Journal of Forecasting, 16(4), 451–476.
- Winters, P. R. (1960). Forecasting sales by exponentially weighted moving averages. Management Science, 6(3), 324–342.
AI의 도움을 받아 작성되었으며 최대한 레퍼런스를 밝히려 노력했으나 오류가 있을 수 있으니 정확한 정보를 다시 한번 확인하시기 바랍니다.
SES는 additive error 등 일정 조건하에서 ARIMA(0,1,1)과 예측식이 연결됩니다. 즉 차분된 시계열이 MA(1)을 따른다고 가정하는 모형의 평활 형태로 볼 수 있습니다. 자세한 도출은 Hyndman et al.(2008) Ch. 11 참고. ↩︎
Holt, C. C. (1957). “Forecasting seasonals and trends by exponentially weighted moving averages.” 처음에는 ONR 메모로 발표됐다가 2004년 International Journal of Forecasting에 재출간되었습니다. ↩︎
Winters, P. R. (1960). “Forecasting sales by exponentially weighted moving averages.” Management Science, 6(3), 324–342. Holt가 추세를, Winters가 계절성을 각각 추가한 형태로 결합되어 “Holt-Winters” 모형으로 불리게 되었습니다. ↩︎
Hyndman, R. J., Koehler, A. B., Snyder, R. D., & Grose, S. (2002). “A state space framework for automatic forecasting using exponential smoothing methods.” International Journal of Forecasting, 18(3), 439–454. ↩︎
2 (error) × 3 (trend) × 3 (seasonal) = 18가지가 기본이고, error와 seasonal의 호환성 조건(곱셈 계절성에 가법 오차 등) 때문에 실제 유효한 모델은 더 적습니다. 자세한 분류는 Hyndman & Athanasopoulos(2021) Section 8.6 참고. ↩︎
상태공간 모형(state space model)은 관측 가능한 변수($y_t$)와 관측 불가능한 상태 변수들($\ell_t, b_t, s_t$)을 분리하여, 상태가 시간에 따라 어떻게 진화하고 그것이 관측치로 어떻게 드러나는지를 두 종류의 방정식(state equation, observation equation)으로 표현하는 틀입니다. 칼만 필터가 같은 틀의 대표적 추정 도구입니다. ↩︎
additive error ETS와 ARIMA 사이의 예측식 연결은 Hyndman, R. J., et al. (2008). Forecasting with Exponential Smoothing: The State Space Approach. Springer, Ch. 11 참고. SES와 ARIMA(0,1,1), Holt’s linear와 ARIMA(0,2,2)의 관계도 같은 책에서 다룹니다. ↩︎
Makridakis, S., & Hibon, M. (2000). “The M3-Competition: results, conclusions and implications.” International Journal of Forecasting, 16(4), 451–476. 이후 M4 (2018), M5 (2020) 대회에서도 단순 모형의 조합이 복잡한 단일 모형 못지않게 좋은 성능을 보인다는 결과가 일관되게 확인되었습니다. ↩︎