Prophet — 회귀 분해로 추세·계절성·이벤트를 한 번에 (1부)
지금까지 ARIMA/SARIMA와 ETS를 살펴봤습니다. 두 모형군은 “과거 관측값의 함수”로 현재를 설명하는 방식입니다. 2017년 Facebook(현 Meta) Research 팀이 발표한 Prophet은 접근법이 다릅니다. 시간 $t$ 자체를 입력으로 받는 회귀 분해 모형입니다.1
1. Prophet의 포지션
| ARIMA | ETS | Prophet | |
|---|---|---|---|
| 핵심 아이디어 | 잔차 자기상관 모델링 | 지수가중 레벨·추세·계절 | 회귀 분해 (추세+푸리에+휴일) |
| 추세 처리 | 차분 | $\ell_t$, $b_t$ 직접 추적 | Piecewise linear / Logistic |
| 복수 계절성 | 어려움 | 어려움 | 자연스럽게 지원 |
| 휴일·이벤트 | 없음 | 없음 | 기본 지원 |
| 결측치·불규칙 간격 | 보간 필요 | 보간 필요 | 비교적 강함. 단, 관측 패턴이 계절성 식별을 방해하지 않는지 확인 필요 |
| 모형 선택 | AIC/BIC 자동 | AIC/BIC 자동 | CV 기반 수동 |
Prophet이 빛나는 영역은 일별 또는 시간별 데이터에 연간·주간·일간 계절성이 겹치고, 휴일·프로모션 같은 이벤트 효과까지 있는 비즈니스 KPI 예측입니다. 웹 트래픽, 앱 DAU, 소매 매출이 대표 사례입니다.
2. 핵심 모형 구조
Prophet의 전체 모형은 덧셈 분해입니다:
\[y(t) = g(t) + s(t) + h(t) + \epsilon_t\]| 항 | 의미 | 방법 |
|---|---|---|
| $g(t)$ | 추세 | Piecewise linear 또는 Logistic growth |
| $s(t)$ | 계절성 | 푸리에 급수 |
| $h(t)$ | 휴일·이벤트 | 지시 변수 선형 회귀 |
| $\epsilon_t$ | 오차 | $N(0, \sigma^2)$ 가정 |
ARIMA나 ETS가 “이전 시점의 값이나 오차를 입력으로 받는 점화식”인 반면, Prophet은 시간 $t$ 자체를 독립변수로 삼는 회귀 모형입니다. 결측치나 불규칙 간격 데이터에 강한 이유이며, 동시에 잔차 자기상관을 모형화하지 못하는 이유이기도 합니다.
3. 추세 컴포넌트 $g(t)$ — Change Points
$g(t)$는 두 가지 형태 중 하나를 선택합니다. 데이터에 성장의 상한이 있는가 라는 질문이 선택 기준입니다.
| 3.1 Piecewise Linear | 3.2 Logistic Growth | |
|---|---|---|
| 성장 형태 | 선형 (무한 연장) | S-curve (포화 수렴) |
| 상한(cap) 필요 | 불필요 | 필수 (사용자 지정) |
| 기본값 | growth='linear' | growth='logistic' |
| 적합 데이터 | 매출, 트래픽 등 지속 성장 | 가입자 수, 시장점유율 등 포화 가능 |
두 모드 모두 change points를 동일한 방식으로 처리합니다. 기울기 변화량 벡터 $\boldsymbol{\delta}$와 Laplace 사전분포를 그대로 씁니다.
3.1 Piecewise Linear Trend
가장 자주 쓰는 기본 모드입니다.
후보 change points 배치
Prophet은 학습 구간 앞 80%에 기본 25개의 후보 change points를 균등 간격으로 배치합니다. 이 위치들이 실제 추세 꺾임인지는 아무도 모릅니다. 단지 “여기서 기울기가 바뀔 수도 있다”는 후보 목록입니다. 나머지 20%는 change point를 두지 않아 미래 예측이 마지막 학습 구간의 추세를 그대로 연장하게 합니다.
후보 사이에서 실제 변화가 일어나면?
실제 통계적 성질 변화가 15번째와 16번째 후보 사이에서 일어난다면, 모형은 가장 가까운 후보(16번째)에 δ를 집중시켜 근사합니다. 탐지 해상도는 후보 간격에 의해 제한됩니다. 1년치 일별 데이터(365일 × 앞 80%)에 25개를 배치하면 후보 간격은 약 12일이므로, 실제 변화 위치와의 최대 오차는 6일 수준입니다. 해상도를 높이려면 n_changepoints를 늘리거나, 변화 시점을 이미 알고 있다면 changepoints=['2022-03-01', ...]로 직접 지정합니다.
$g(t)$가 change point를 만날 때마다 기울기가 바뀐다
\[g(t) = \bigl(k + \mathbf{a}(t)^T \boldsymbol{\delta}\bigr)\,t + \bigl(m + \mathbf{a}(t)^T \boldsymbol{\gamma}\bigr)\]수식의 두 항은 직선의 기본 형태 $y = \text{기울기} \times t + \text{절편}$에 대응합니다.
| 항 | 역할 | 구성 |
|---|---|---|
| $\bigl(k + \mathbf{a}(t)^T\boldsymbol{\delta}\bigr)\,t$ | 기울기 × $t$ | $k$: 기준 기울기, $\mathbf{a}(t)^T\boldsymbol{\delta}$: 통과한 CP의 $\delta$ 누적합 |
| $m + \mathbf{a}(t)^T\boldsymbol{\gamma}$ | 절편 | $m$: 기준 절편, $\mathbf{a}(t)^T\boldsymbol{\gamma}$: 절편 보정 누적합 |
$\mathbf{a}(t)$는 $t$가 $j$번째 change point $s_j$를 지났으면 1, 아직 못 지났으면 0인 지시 벡터입니다. 두 항 모두에 $\mathbf{a}(t)$가 등장하는 이유는 change point 통과 시 기울기만 바꾸면 그래프에 단절(jump)이 생기기 때문입니다.
왜 절편($\boldsymbol{\gamma}$)도 함께 바꿔야 하는가
change point $s_j$ 직전과 직후에서 $g(t)$ 값이 같으려면, 기울기가 $\delta_j$만큼 바뀌는 순간 절편도 $-\delta_j \cdot s_j$만큼 보정되어야 합니다:
\[\gamma_j = -\delta_j \cdot s_j\]기울기가 올라가면($\delta_j > 0$) 절편은 그만큼 내려가야 change point 위치에서 선이 끊기지 않습니다. $\boldsymbol{\gamma}$는 자유 모수가 아니라 $\boldsymbol{\delta}$와 $s_j$로부터 자동 결정됩니다 — Prophet이 추정하는 실질적인 미지수는 $\boldsymbol{\delta}$ 하나뿐입니다.
$\mathbf{a}(t)^T \boldsymbol{\delta}$는 $t$ 이전에 통과한 모든 change point의 $\delta_j$를 합산합니다. 즉:
\[\text{현재 기울기} = k + \sum_{j:\, s_j \leq t} \delta_j\]$g(t)$가 $s_j$를 지나는 순간 기울기에 $\delta_j$가 더해집니다. $\delta_j = 0$이면 그 change point는 사실상 비활성화 — 통과해도 아무 변화가 없습니다.
두 가지를 명확히 해두면 혼동이 줄어듭니다.
① $\delta_j$는 기울기가 아니라 기울기 변화량(증분)입니다. 구간 $[s_j, s_{j+1})$ 안에서의 실제 기울기는 $k$에 그 이전 모든 $\delta$를 누적합산한 값입니다:
\[\text{구간 } [s_j, s_{j+1})\text{ 의 기울기} = k + \delta_1 + \delta_2 + \cdots + \delta_j\]예를 들어 $k=1$이고 $\delta_1=0.5,\, \delta_2=-0.3$이면, 세 번째 구간의 기울기는 $1 + 0.5 + (-0.3) = 1.2$입니다. $\delta_2$가 음수라고 추세가 하락하는 게 아니라, 이전 구간보다 기울기가 0.3 줄어든 것입니다.
② 구간 안에서 기울기는 완전히 고정됩니다. $\mathbf{a}(t)$는 새로운 $s_j$를 통과할 때만 바뀝니다. 두 change point 사이에서는 $\mathbf{a}(t)$가 변하지 않으므로 기울기도 상수입니다. 따라서 $g(t)$는 각 구간이 직선인 꺾은선(piecewise linear) 함수입니다 — change point에서만 꺾이고, 구간 내부는 직선입니다.
왜 누적합인가 — 설계 선택의 논리
구간별로 절대 기울기 $\beta_j$를 직접 추정하는 방식도 가능합니다. 그런데 Prophet의 누적합 방식은 이와 수학적으로 완전히 동치입니다. 단지 파라미터화가 다를 뿐입니다:
\[\delta_j = \beta_j - \beta_{j-1} \quad \text{(인접 구간의 기울기 차이)}\]이렇게 두면 Laplace 사전분포가 딱 맞아 떨어집니다. $\delta_j = 0$은 “이 change point에서 기울기 변화 없음”을 직접 의미하므로, Laplace$(0, \tau)$로 $\delta_j$를 0 쪽으로 수축시키는 것이 곧 “대부분의 change point를 비활성화한다”는 뜻이 됩니다.
절대 기울기 $\beta_j$를 추정하는 방식이었다면 “이 change point에서 변화 없음”은 $\beta_j = \beta_{j-1}$, 즉 인접한 두 파라미터가 같아야 한다는 조건이 됩니다. 이를 사전분포로 표현하려면 훨씬 복잡한 구조가 필요합니다.
물리적으로는 $\delta_j$를 “그 시점부터 기울기에 영구히 가해진 힘”으로 볼 수 있습니다. 한번 가해진 힘은 이후 change point가 반대 방향으로 상쇄하기 전까지 계속 작용합니다. 누적합은 그 “아직 상쇄되지 않은 힘의 합산”입니다.
Laplace 사전분포와 LASSO — change point “감지”의 실체
먼저 짚을 점이 있습니다. Prophet은 변화점을 검정이나 CUSUM 같은 알고리즘으로 “탐지”하지 않습니다. 25개 후보 각각에 $\delta_j$ 파라미터를 붙이고, 모든 $\delta_j$를 데이터에 맞게 동시 추정합니다.
- $\delta_j \approx 0$ → 해당 후보는 변화 없음 (소거됨)
- $\delta_j \neq 0$ → 해당 후보에서 추세가 꺾임 (활성화됨)
“감지”의 실체는 25개 δ 파라미터의 사후 추정 결과입니다. 그렇다면 왜 대부분의 $\delta_j$가 0으로 수렴하는가 — 여기서 Laplace 사전분포가 등장합니다.
\[\delta_j \sim \text{Laplace}(0,\, \tau)\]$\tau$ = changepoint_prior_scale (기본값 0.05)
MLE는 가능도 $P(X \mid \theta)$만 최대화하는 반면, MAP는 가능도에 사전분포 $P(\theta)$를 곱한 사후 분포를 최대화합니다(→ 모수 추정과 가능도의 직관, MAP와 베이지안 회귀). 둘 다 $\arg\max$로 정식화되는 점 추정이지만, 사전분포가 추가되느냐의 차이가 있습니다.
| MLE | MAP | |
|---|---|---|
| 목적함수 | $P(X \mid \theta)$ | $P(\theta \mid X) \propto P(X \mid \theta) \cdot P(\theta)$ |
| 사전분포 | 없음 | 있음 |
| 데이터 부족 시 | 과적합 위험 | 사전분포가 완화 |
MLE는 데이터만 보고 판단하는 반면, MAP는 사전분포 형태의 사전 지식을 추정에 반영합니다. 많이 쓰는 정규화 기법들이 사실 MAP 추정의 특수한 형태라는 점도 이로부터 나옵니다.
| 사전분포 | MAP 동치 |
|---|---|
| 균등분포 (Uniform) | MAP = MLE |
| Gaussian $N(0, \sigma^2)$ | L2 규제 (Ridge) |
| Laplace$(0, \tau)$ | L1 규제 (LASSO) |
Prophet의 경우 핵심 항만 단순화해서 MAP 추정의 목적함수를 전개하면:
\[\log p(\mathbf{y} \mid \boldsymbol{\delta}) + \log p(\boldsymbol{\delta}) = -\sum(\text{잔차})^2 - \frac{1}{\tau}\sum_j |\delta_j|\]이것이 LASSO(L1 정규화) 목적함수입니다 ($\lambda = 1/\tau$). Ridge(L2)가 계수를 0 근처로 수축시키는 데 그치는 반면, LASSO는 작은 계수를 0으로 강하게 수축시키고 MAP 최적화에서는 sparse한 해를 만들 수 있습니다. 이유는 제약 경계의 모양 차이입니다. L2 제약은 원형이라 잔차 등고선이 경계 위 어느 점과도 만날 수 있지만, L1 제약은 마름모형이라 등고선이 꼭짓점(= 특정 $\delta_j = 0$인 점)에서 만날 가능성이 높습니다.
$\tau$가 작을수록 패널티 $1/\tau$가 커져 더 많은 $\delta_j$가 0으로 수렴하고 추세가 완만해집니다. 클수록 더 많은 change point가 활성화되어 추세가 유연해지지만 과적합 위험이 있습니다.2
Laplace 분포의 확률밀도함수는 $f(x) = \frac{1}{2\tau}\exp!\left(-\frac{\lvert x\rvert}{\tau}\right)$입니다. 정규분포가 $e^{-x^2}$으로 감소하는 반면 Laplace는 $e^{-\lvert x\rvert}$으로 감소해 0 근방에서 훨씬 뾰족하고, 꼬리는 더 두껍습니다.
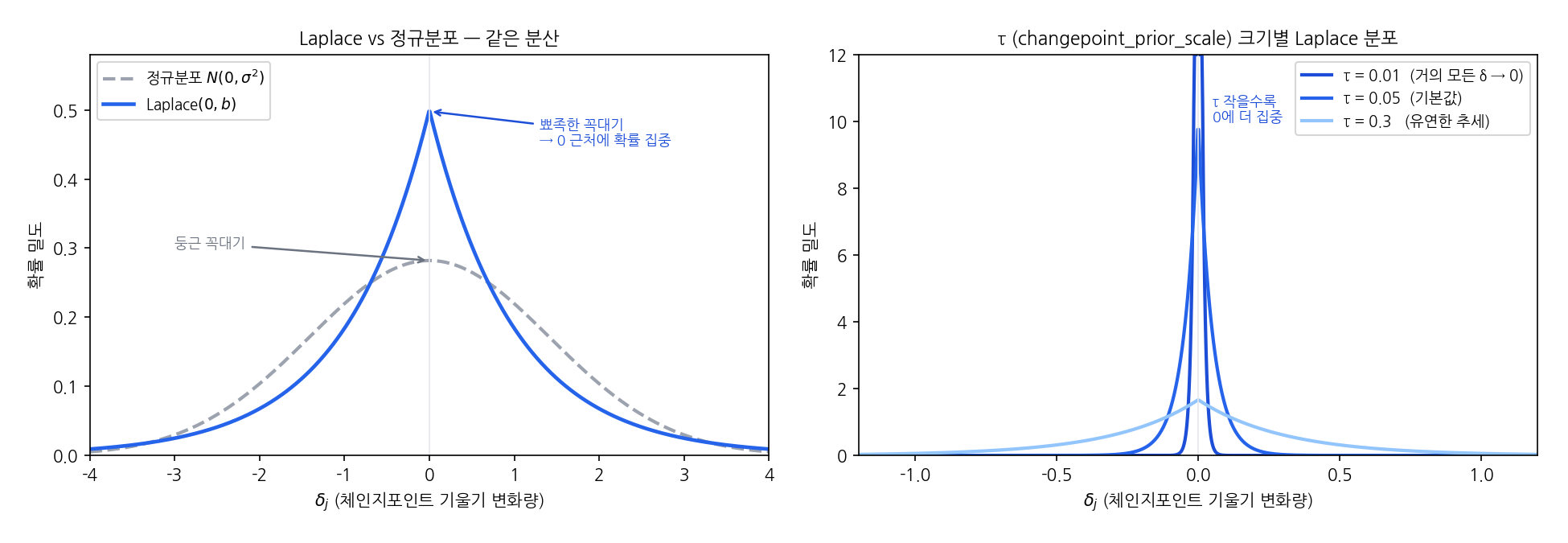
왼쪽 그래프는 같은 분산 조건에서 Laplace(파란 실선)와 정규분포(회색 점선)를 비교합니다. Laplace가 0에서 훨씬 뾰족하게 솟아오르며 0 근처에 확률이 집중되어 있습니다. 오른쪽은 changepoint_prior_scale($\tau$) 값에 따른 Laplace 분포 형태 변화로, $\tau$가 작을수록 분포가 0에 극도로 집중됩니다.
MAP 해는 잔차 등고선(타원)과 사전분포 제약 경계가 처음 만나는 점입니다.
- L2 (Ridge / 정규분포): 원형 경계 → 등고선이 경계 위 어느 점과도 만날 수 있어 $\delta_j = 0$이 나오기 어려움
- L1 (LASSO / Laplace): 마름모 경계 → 꼭짓점이 축 위에 있어($\delta_j = 0$인 점) 등고선이 꼭짓점에서 만날 가능성이 높음 → 스파스 해 자연스럽게 생성
| 사전분포 | MAP 동치 | 효과 |
|---|---|---|
| 정규분포 $N(0, \sigma^2)$ | Ridge (L2) | 0 근처로 수축, 완전한 0은 드물다 |
| Laplace$(0, \tau)$ | LASSO (L1) | 작은 값을 0으로 강하게 수축시키며 MAP에서는 sparse한 해를 만들 수 있다 |
아래는 후보 change points 중 일부만 활성화된 $g(t)$ 예시입니다. 빨간 점선 위치에서 기울기가 실제로 꺾이고, 노란 점선 위치는 $\delta_j = 0$으로 소거되어 아무 변화가 없습니다.
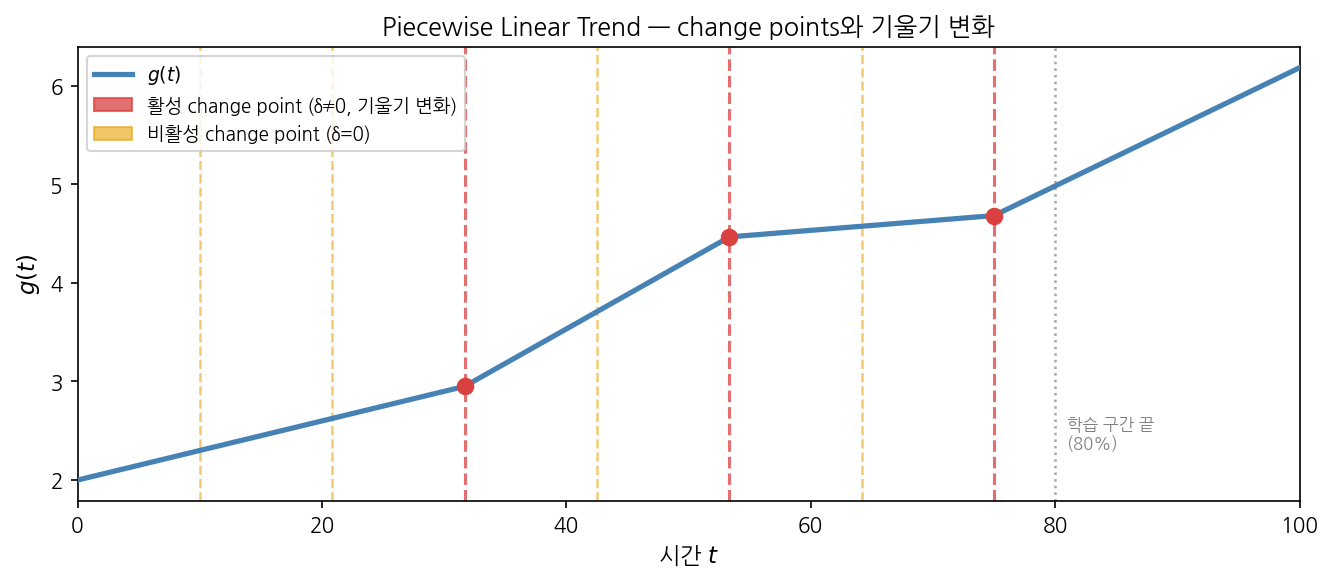
이 change point 메커니즘이 Prophet의 Regime Change 대응입니다. 다만 다루는 것은 추세 기울기의 변화이며, 분산 구조나 계절 패턴 자체의 변화는 대상 밖입니다.
3.2 Logistic Growth (포화 성장)
신규 가입자 수, 시장 점유율, 바이럴 확산처럼 성장이 언젠가 천장에 수렴하는 데이터에 씁니다. 개념적으로는 기본 로지스틱 함수에 change points를 결합한 형태입니다. 실제 Prophet 구현은 change point 이후에도 곡선이 연속적으로 이어지도록 조정항을 포함합니다.
\[g(t) = \frac{L(t)}{1 + \exp\!\bigl(-(k + \mathbf{a}(t)^T \boldsymbol{\delta})\,(t - (m + \mathbf{a}(t)^T \boldsymbol{\gamma}))\bigr)}\]3.1의 식과 비교하면 구조가 그대로 유지됩니다. $k$와 $m$을 분모의 지수 안으로 집어넣었을 뿐이고, $\boldsymbol{\delta}$와 $\boldsymbol{\gamma}$는 완전히 동일한 change point 메커니즘입니다. change point가 활성화되면 S-curve의 기울기(성장 속도)가 꺾입니다.
$L(t)$: 시간에 따라 변하는 포화 상한
$L(t)$는 단순한 상수가 아닙니다. 시간에 따라 달라지는 포화 상한을 지정할 수 있습니다. 예를 들어 글로벌 시장으로 확장하면서 TAM(Total Addressable Market)이 커지는 경우, 해당 시점부터 $L$을 높게 설정할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from prophet import Prophet
import pandas as pd
# growth='logistic' 사용 시 데이터프레임에 'cap' 열이 필수
df['cap'] = 8.5 # 포화 상한 (log 조회수 기준)
# 시점별로 상한이 달라지는 경우
df.loc[df['ds'] > '2014-01-01', 'cap'] = 10.0 # 이후 상한 상향
model = Prophet(growth='logistic')
model.fit(df)
future = model.make_future_dataframe(periods=365)
future['cap'] = 10.0 # 미래 데이터에도 cap 지정 필수
forecast = model.predict(future)
cap을 빠뜨리면 에러가 납니다. 반대로 growth='linear'일 때는 cap이 없어도 됩니다.
3.1 vs 3.2 — 어떤 모양의 g(t)를 얻는가
3.1은 꺾인 직선들의 연결입니다. 추세가 오르내릴 수 있고 상한이 없습니다. 3.2는 S자를 그리면서 결국 $L(t)$에 수렴합니다. change point가 붙으면 S-curve의 기울기가 중간에 달라집니다. 가파르게 성장하다가 갑자기 속도가 줄어드는 모양을 자연스럽게 표현합니다.
언제 Logistic을 써야 하는가. 포화 상한이 도메인 지식으로 명확히 존재할 때 씁니다. $L$을 너무 낮게 잡으면 모형이 이미 포화된 것처럼 행동하고, 너무 높게 잡으면 사실상 선형 모형과 다르지 않게 됩니다. 상한에 대한 확신이 없으면
growth='linear'가 더 안전합니다.
4. 계절성 컴포넌트 $s(t)$ — 푸리에 급수
계절성을 푸리에 급수로 표현합니다:
\[s(t) = \sum_{n=1}^{N} \left( a_n \cos\frac{2\pi n t}{P} + b_n \sin\frac{2\pi n t}{P} \right)\]- $P$: 계절 주기 (연간 365.25일, 주간 7일)
- $N$: 푸리에 차수 — 클수록 계절 패턴이 유연 (기본값: 연간 10, 주간 3)
- $a_n, b_n$: 추정할 회귀 계수
여러 주기를 동시에 stacking할 수 있습니다. 시간별 데이터라면 일간($P=24$) + 주간($P=168$) + 연간($P=8766$)을 동시에 적합할 수 있습니다. ETS와 SARIMA가 단일 계절 주기를 가정하는 것과 대조적입니다.
계절 계수에는 정규 사전분포가 붙습니다:
\[\beta_n \sim N(0,\, \sigma_s^2)\]seasonality_prior_scale($\sigma_s$, 기본값 10)로 유연성을 조절합니다.
5. 휴일·이벤트 컴포넌트 $h(t)$
각 이벤트를 지시 변수로 표현합니다:
\[h(t) = \mathbf{Z}(t)\,\boldsymbol{\kappa}\]- $\mathbf{Z}(t)$: $t$가 특정 이벤트 윈도우 안에 있는지 나타내는 지시 행렬
- $\boldsymbol{\kappa}$: 이벤트 효과 크기 (추정 대상)
1
2
3
4
5
6
7
8
9
10
11
12
from prophet import Prophet
import pandas as pd
# 설날·추석 같은 한국 공휴일 지정 예시
kr_holidays = pd.DataFrame({
'holiday': 'lunar_new_year',
'ds': pd.to_datetime(['2020-01-24', '2021-02-12', '2022-02-01']),
'lower_window': -1, # 하루 전부터 효과 인정
'upper_window': 3, # 사흘 후까지 효과 인정
})
model = Prophet(holidays=kr_holidays)
lower_window, upper_window로 이벤트 효과가 미치는 날짜 범위를 조절합니다. 휴일 계수에도 정규 사전분포(holidays_prior_scale, 기본값 10)가 붙습니다.
6. 가법 vs 승법 계절성
기본은 가법 $y = g + s + h + \epsilon$입니다.
계절 진폭이 추세 수준에 비례해 커지는 경우(Air Passengers가 대표 예)에는 승법을 씁니다:
\[y(t) = g(t) \cdot \bigl(1 + s(t) + h(t)\bigr) + \epsilon_t\]1
2
# 승법 계절성
Prophet(seasonality_mode='multiplicative')
ETS는 (A,A,A) vs (A,A,M) 같은 조합을 AIC로 자동 선택하지만, Prophet은 사용자가 직접 지정해야 합니다. 데이터를 시각화해 계절 진폭이 일정하면 가법, 추세에 비례해 커지면 승법을 선택합니다.
7. 적합 방법 — Stan 백엔드의 베이즈 MAP
Stan이란?
Stan은 베이지안 통계 모형을 위한 확률적 프로그래밍 언어(Probabilistic Programming Language) 이자 추론 엔진입니다.3 2012년 Columbia 대학교의 Andrew Gelman 연구팀이 개발해 오픈소스로 공개했으며, 이름은 몬테카를로 방법의 공동 창안자인 Stanisław Ulam에서 따왔습니다.
Stan이 하는 일을 단계로 나누면:
- 모형 기술: Stan 전용 언어(
.stan파일)로 likelihood와 사전분포를 작성 - 컴파일: Stan 코드를 C++로 변환 및 컴파일
- 추론: HMC-NUTS(Monte Carlo 샘플링) 또는 L-BFGS(최적화)로 모수 추정
Prophet의 핵심 모형($g + s + h$)은 Stan 코드 파일로 구현되어 있습니다. model.fit()을 호출하면 내부적으로 Stan을 실행해 모수를 추정하고 결과를 Python으로 돌려줍니다.
Stan은 Prophet과 완전히 독립적인 범용 도구입니다. 생태학(개체수 동태 모형), 의학(임상 시험 분석), 경제학(거시 모형) 등 베이지안 추론이 필요한 곳이라면 어디서든 쓰입니다. R에서는 rstan, brms, rstanarm이 Stan을 래핑하는 대표적인 패키지이고, Python에서는 cmdstanpy와 pystan이 인터페이스 역할을 합니다. 최근 Python Prophet은 보통 cmdstanpy 백엔드를 사용하며, 환경과 버전에 따라 CmdStan(독립 실행형 Stan) 설치나 설정이 추가로 필요할 수 있습니다.
왜 Prophet이 Stan을 선택했나. Prophet의 모형은 change point 기울기 $\boldsymbol{\delta}$에 Laplace 사전분포를, 푸리에 계수 $\boldsymbol{\beta}$에 정규 사전분포를 주는 구조입니다. 이처럼 사전분포가 명시적으로 지정된 베이지안 모형은 Stan이 가장 자연스럽게 표현하고 효율적으로 추론합니다. MLE 기반의 statsmodels나 sklearn과는 설계 철학이 다릅니다.
라이선스와 상업적 이용. Prophet은 MIT 라이선스, Stan(CmdStan)은 BSD-3-Clause를 적용합니다. 둘 다 상업적 이용이 자유로운 오픈소스 라이선스입니다. 제품이나 서비스에 Prophet을 내장하거나 사내 예측 시스템에 활용해도 라이선스 제약이 없습니다.4
MAP vs MCMC
Stan은 두 가지 추론 모드를 모두 지원하며, Prophet이 이를 그대로 노출합니다.
기본 (MAP): L-BFGS로 사후 최빈값(Maximum A Posteriori)을 최적화합니다. 빠르고 실전에서 충분합니다.
선택 옵션 (MCMC): HMC-NUTS로 사후 분포 전체를 샘플링합니다. 예측 불확실성 구간이 통계적으로 더 정확해지지만 수십 배 느립니다.
1
2
3
4
5
# 기본: MAP (Stan L-BFGS)
model = Prophet()
# MCMC: Stan HMC-NUTS, 1000 샘플
model = Prophet(mcmc_samples=1000)
추정되는 주요 모수:
| 모수 | 사전분포 | 역할 |
|---|---|---|
| $k$, $m$ | 정규 | 기준 성장률·오프셋 |
| $\boldsymbol{\delta}$ | Laplace$(0, \tau)$ | change point 기울기 변화 |
| $\boldsymbol{\beta}$ | $N(0, \sigma_s^2)$ | 푸리에 계수 |
| $\boldsymbol{\kappa}$ | $N(0, \sigma_h^2)$ | 휴일 효과 |
| $\sigma$ | 양수 제약하에서 추정 | 잔차 표준편차 |
8. 모형 선택 — AIC/BIC 없음, CV로 대체
CV(Cross Validation, 교차검증)는 데이터 일부를 학습에서 빼두었다가 예측 오차를 측정하는 데 쓰는 기법입니다. 학습 데이터 안에서 “보지 않은 데이터에 대한 성능”을 추정하는 것이 핵심입니다.
여기서 모형 선택이란 모형 구조(ARIMA vs Prophet 같은 선택)가 아니라 하이퍼파라미터 선택을 뜻합니다. changepoint_prior_scale, seasonality_prior_scale, 푸리에 항 수($N$) 같은 값은 데이터에서 직접 추정되지 않고 사용자가 지정합니다. 이 값들을 잘못 고르면 과소적합·과적합이 생기므로, 여러 후보 조합을 CV로 평가해 예측 오차가 가장 낮은 조합을 고르는 것이 “모형 선택”입니다.
8.1 왜 CV를 쓰는가
ARIMA의 auto.arima나 ETS의 auto_ets는 AIC/BIC를 기준으로 모형 공간을 탐색합니다. AIC/BIC는 “학습 데이터에서 측정한 적합도 — 복잡도 패널티”를 계산하는데, 이를 위해 모형의 자유 모수 수($k$)가 비교적 명확해야 합니다.
Prophet은 ARIMA/ETS처럼 패키지가 AIC/BIC 기반 자동 모형 선택을 제공하지 않습니다. change point prior, seasonality prior 같은 정규화 요소 때문에 단순한 모수 개수 기반 비교가 덜 직관적이고, 실무적으로는 미래 예측 성능을 직접 보는 rolling-origin CV가 권장됩니다. 물론 정규화 모형에서도 effective degrees of freedom, WAIC, LOO 같은 기준을 생각할 수 있지만, Prophet의 표준 튜닝 흐름은 CV에 가깝습니다.
8.2 Rolling-origin CV 작동 원리
Prophet의 교차검증은 Rolling-origin evaluation (또는 walk-forward validation)입니다. 시간축을 따라 학습 윈도우를 앞으로 밀면서 예측을 반복합니다.
세 파라미터가 윈도우 구조를 결정합니다:
1
2
3
4
5
6
전체 데이터: |←────────────── T ──────────────────────────→|
1회차: |←── initial ──→|←── horizon ──→|
2회차: |←── initial + period ──→|←── horizon ──→|
3회차: |←── initial + 2×period ──→|←── horizon ──→|
...
initial: 첫 번째 학습에 쓸 데이터 길이. 계절성 주기를 충분히 포함해야 하므로 연간 데이터라면 최소 1년, 권장 2년 이상.period: 커트오프(cutoff)를 얼마씩 앞으로 이동할지. 작을수록 평가 윈도우가 많아져 더 안정적이지만 느려집니다.horizon: 각 커트오프에서 얼마나 앞을 예측할지. 실제 운영 예측 지평과 맞추는 것이 원칙입니다.
1
2
3
4
5
6
7
8
9
10
from prophet.diagnostics import cross_validation, performance_metrics
df_cv = cross_validation(
model,
initial='730 days', # 첫 학습: 최소 2년치
period='180 days', # 6개월마다 커트오프 이동
horizon='365 days', # 1년 앞까지 예측 평가
parallel='processes', # 병렬 처리 (데이터가 길면 필수)
)
# df_cv 컬럼: ds, yhat, yhat_lower, yhat_upper, y, cutoff
결과 데이터프레임에는 각 (cutoff, ds) 조합마다 예측값과 실제값이 쌓입니다. 같은 ds 시점이라도 여러 커트오프에서 예측됐다면 여러 행이 생깁니다.
8.3 성능 지표 집계
performance_metrics()는 horizon 기준으로 지표를 집계합니다. “커트오프로부터 30일 뒤 예측은 얼마나 정확한가”, “180일 뒤는?” 식으로 예측 지평에 따른 성능 저하 곡선을 볼 수 있습니다.
1
2
3
4
5
6
df_p = performance_metrics(df_cv)
print(df_p[['horizon', 'mape', 'rmse', 'coverage']].head(10))
# horizon: 예측 지평 (1day, 2days, ...)
# mape : Mean Absolute Percentage Error
# rmse : Root Mean Squared Error
# coverage: 실제값이 80% 예측 구간 안에 드는 비율
rolling_window=1을 주면 horizon별 단일 값, 기본값(0.1)을 쓰면 인접 horizon 구간의 이동평균으로 부드럽게 집계합니다.
8.4 하이퍼파라미터 그리드 서치
CV를 평가 도구로 삼아 후보 조합을 전부 돌려보는 것이 Prophet의 표준 튜닝 절차입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
from itertools import product
import numpy as np
param_grid = {
'changepoint_prior_scale': [0.001, 0.01, 0.05, 0.1, 0.5],
'seasonality_prior_scale': [0.1, 1.0, 10.0 ],
'seasonality_mode': ['additive', 'multiplicative'],
}
all_params = [dict(zip(param_grid.keys(), v))
for v in product(*param_grid.values())]
# 총 5 × 3 × 2 = 30 조합
mapes = []
for params in all_params:
m = Prophet(**params).fit(df)
df_cv = cross_validation(m, initial='730 days',
period='180 days', horizon='365 days',
parallel='processes')
df_p = performance_metrics(df_cv, rolling_window=1)
mapes.append(df_p['mape'].mean())
best = all_params[np.argmin(mapes)]
print(f"최적 파라미터: {best}")
print(f"최적 MAPE: {min(mapes):.4f}")
조합이 많으면 시간이 걸립니다. 실용적인 순서는:
seasonality_mode먼저 시각적으로 판단 (계절 진폭 확인)changepoint_prior_scale을 로그 스케일로 탐색 (가장 중요)seasonality_prior_scale은 기본값 10에서 크게 벗어나지 않는 경우가 많음holidays_prior_scale은 holiday 데이터가 있을 때만 튜닝
8.5 주요 하이퍼파라미터 정리
| 파라미터 | 기본값 | 범위 | 역할 |
|---|---|---|---|
changepoint_prior_scale | 0.05 | 0.001–0.5 | 추세 유연성. 클수록 꺾임 많음. 가장 먼저 조정 |
seasonality_prior_scale | 10 | 0.01–10 | 계절성 진폭 허용 범위 |
holidays_prior_scale | 10 | 0.01–10 | 휴일 효과 크기 |
seasonality_mode | 'additive' | — | 가법 vs 승법. 시각 판단 우선 |
n_changepoints | 25 | 5–50 | 후보 change point 수. prior_scale로 조절하는 편이 낫다 |
changepoint_prior_scale이 너무 작으면 추세가 거의 직선에 가까워 실제 변화를 못 따라갑니다. 너무 크면 학습 데이터의 잡음까지 추세로 흡수해 테스트 오차가 올라갑니다. CV MAPE 곡선이 특정 값에서 U자 최저점을 그리면 그게 최적입니다.
모형 구조와 추정 원리는 여기까지입니다. 실제 예시·ARIMA/ETS 비교·앙상블·활용 판단 기준은 2부에서 이어집니다.
참고문헌
- Taylor, S. J., & Letham, B. (2018). Forecasting at scale. The American Statistician, 72(1), 37–45. DOI: 10.1080/00031305.2017.1380080
- Carpenter, B., Gelman, A., Hoffman, M. D., Lee, D., Goodrich, B., Betancourt, M., Brubaker, M., Guo, J., Li, P., & Riddell, A. (2017). Stan: A probabilistic programming language. Journal of Statistical Software, 76(1), 1–32.
AI의 도움을 받아 작성되었으며 최대한 레퍼런스를 밝히려 노력했으나 오류가 있을 수 있으니 정확한 정보를 다시 한번 확인하시기 바랍니다.
Taylor, S. J., & Letham, B. (2018). Forecasting at scale. The American Statistician, 72(1), 37–45. DOI: 10.1080/00031305.2017.1380080. 원래 2017년 PeerJ Preprints로 먼저 공개됐으며, Facebook 내부의 수백 개 시계열 예측 파이프라인을 자동화한 경험에서 출발한 논문입니다. ↩︎
Change point 탐지의 상세 수식 유도는 Taylor & Letham(2018) Appendix를 참고하세요. ↩︎
Carpenter, B., Gelman, A., Hoffman, M. D., Lee, D., Goodrich, B., Betancourt, M., Brubaker, M., Guo, J., Li, P., & Riddell, A. (2017). Stan: A probabilistic programming language. Journal of Statistical Software, 76(1), 1–32. DOI: 10.18637/jss.v076.i01. Stan 공식 사이트: mc-stan.org. ↩︎
Prophet GitHub: github.com/facebook/prophet (MIT License). Stan(CmdStan) GitHub: github.com/stan-dev/cmdstan (BSD-3-Clause). 두 라이선스 모두 저작권 표시를 유지하는 조건 하에 복사·수정·배포·상업적 이용이 자유롭습니다. ↩︎