L1·L2 규제: Lasso와 Ridge의 원리부터 실전까지
서론
모델을 학습하다 보면 훈련 데이터에는 잘 맞지만 새로운 데이터에는 맥을 못 추는 과적합(overfitting) 문제를 자주 마주칩니다.
규제(regularization)는 이 문제를 다루는 대표적인 기법으로, 손실 함수에 패널티 항을 더해 모델이 지나치게 복잡해지는 것을 억제합니다.
이 포스팅에서는 가장 많이 쓰이는 두 가지 규제 방식을 정리합니다.
- L2 규제 (Ridge) — 가중치를 전체적으로 줄인다
- L1 규제 (Lasso) — 가중치를 0으로 만들어 특성을 선택한다
- 왜 L1은 sparse하고 L2는 smooth한가 — 기하학적 관점
- 실전 코드와 확인 방법
1. 규제가 없으면 어떤 일이 일어나는가
선형 회귀는 잔차 제곱합(RSS)을 최소화합니다.
\[\text{RSS}(\mathbf{w}) = \sum_{i=1}^{n} \left( y_i - \mathbf{w}^\top \mathbf{x}_i \right)^2\]특성 수가 많거나 데이터가 적으면, 모델은 훈련 데이터의 노이즈까지 외워버립니다. 일부 $w_j$가 매우 크게 추정되어 분산이 폭발합니다. 특성들 사이에 강한 선형 상관(다중공선성)이 있으면 더욱 불안정해집니다.
편향-분산 트레이드오프: 규제를 강하게 주면 편향은 늘지만 분산은 줄어들어, 전반적인 테스트 오차가 감소할 수 있습니다.
2. L2 규제 — Ridge
2.1 목적 함수
\[\mathcal{L}_{\text{Ridge}} = \text{RSS} + \lambda \sum_{j=1}^{p} w_j^2\]패널티 항 $\lambda |\mathbf{w}|_2^2$이 모든 가중치의 제곱합을 억제합니다.
$\lambda$가 클수록 계수를 강하게 0 방향으로 밀어붙입니다. $\lambda \to \infty$이면 모든 계수가 0에 가까워집니다.
Ridge는 $X^\top X + \lambda I$ 형태로 역행렬을 계산하기 때문에, 다중공선성으로 불안정한 상황에서도 안정적으로 해를 구할 수 있습니다.
2.2 핵심 특성
| 항목 | 내용 |
|---|---|
| 패널티 | $\lambda \sum w_j^2$ (L2-norm의 제곱) |
| 계수 거동 | 0에 가깝게 수축하지만, 정확히 0이 되진 않음 |
| 특성 선택 | 불가 (모든 특성이 모델에 남음) |
| 다중공선성 | 강건 |
| 미분 가능 | 모든 점에서 가능 |
3. L1 규제 — Lasso
3.1 목적 함수
\[\mathcal{L}_{\text{Lasso}} = \text{RSS} + \lambda \sum_{j=1}^{p} |w_j|\]패널티가 $|\mathbf{w}|_1$, 즉 절댓값의 합으로 바뀝니다.
3.2 핵심 특성
| 항목 | 내용 |
|---|---|
| 패널티 | $\lambda \sum \lvert w_j \rvert$ (L1-norm) |
| 계수 거동 | 일부 계수가 정확히 0이 됨 |
| 특성 선택 | 가능 (희소 모델 생성) |
| 다중공선성 | 상관된 특성 중 하나만 선택하는 경향 |
| 미분 가능 | $w_j = 0$에서 미분 불가 |
4. 왜 L1은 0을 만들고 L2는 만들지 않는가
제약 최적화 문제로 바꿔 쓰면 이해하기 쉽습니다.
- Ridge: $|\mathbf{w}|_2^2 \le t$ 조건 하에 RSS 최소화 → 제약 영역이 구(ball)
- Lasso: $|\mathbf{w}|_1 \le t$ 조건 하에 RSS 최소화 → 제약 영역이 다이아몬드(마름모)
RSS의 등고선(타원)이 제약 영역과 처음 만나는 점이 해입니다.
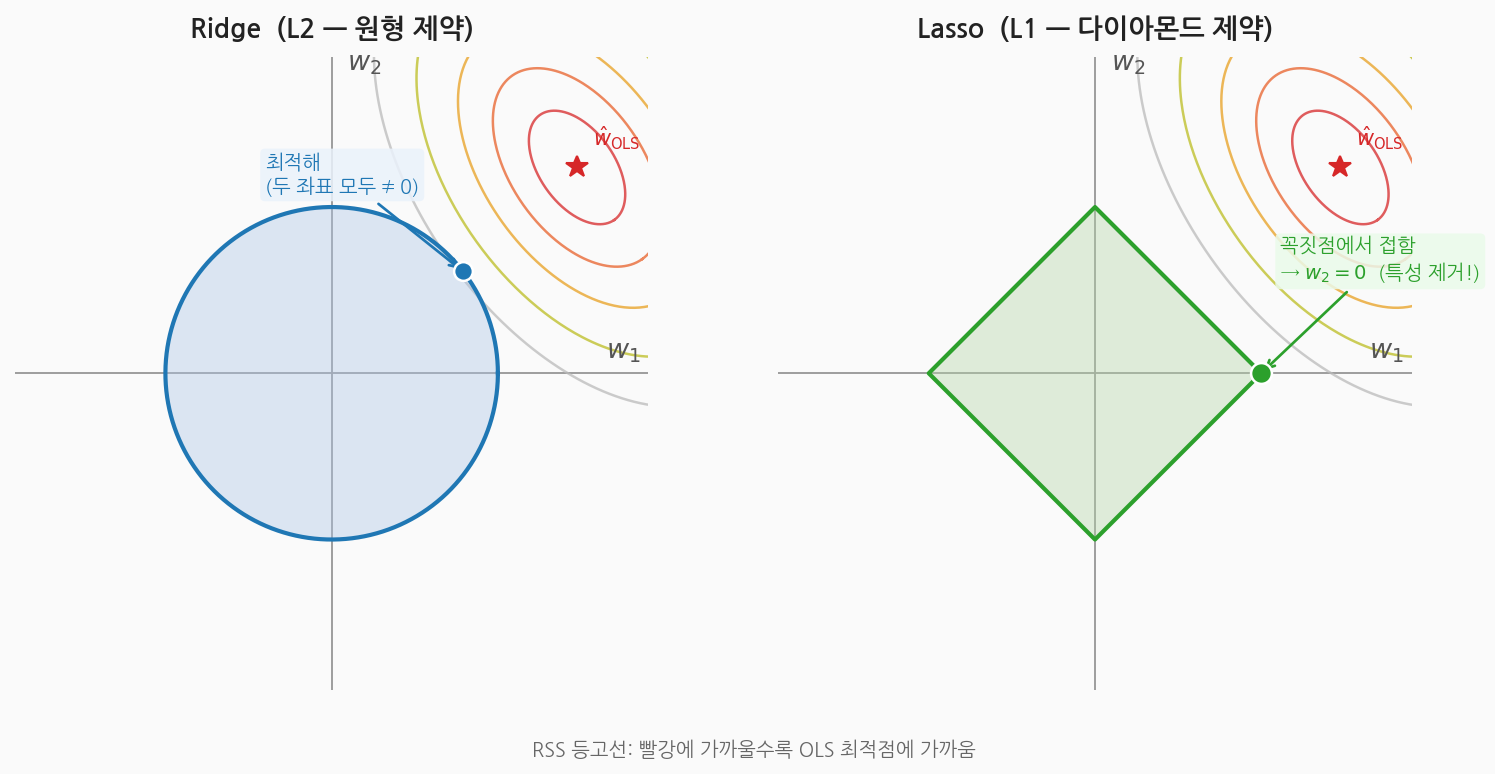 RSS 등고선(타원)이 제약 영역과 처음 만나는 점이 해. Ridge는 원의 곡면 위, Lasso는 다이아몬드의 꼭짓점 위.
RSS 등고선(타원)이 제약 영역과 처음 만나는 점이 해. Ridge는 원의 곡면 위, Lasso는 다이아몬드의 꼭짓점 위.
L1의 다이아몬드는 꼭짓점(vertex)이 축 위에 있습니다. 등고선이 꼭짓점에서 접하면 해당 좌표는 정확히 0이 됩니다. 고차원에서는 꼭짓점이 많아질수록 희소해집니다.
L2의 구는 꼭짓점이 없으므로, 등고선이 어디서 접하든 두 좌표가 동시에 0이 될 가능성은 매우 낮습니다.
5. $\lambda$ 값의 역할
\[\lambda = 0 \Rightarrow \text{규제 없음 (OLS)} \quad\quad \lambda \to \infty \Rightarrow \text{모든 계수} \to 0\]| $\lambda$ | 편향 | 분산 | 적합 |
|---|---|---|---|
| 작다 | 낮음 | 높음 | 과적합 위험 |
| 적절 | 중간 | 중간 | 최적 |
| 크다 | 높음 | 낮음 | 과소적합 |
최적 $\lambda$는 교차 검증(cross-validation) 으로 탐색합니다.
6. Elastic Net — L1과 L2의 혼합
Lasso는 상관된 특성이 있을 때 그 중 하나만 선택하고 나머지를 버리는 경향이 있습니다. Elastic Net은 두 패널티를 선형 결합합니다.
\[\mathcal{L}_{\text{ElasticNet}} = \text{RSS} + \lambda \left[ \rho \|\mathbf{w}\|_1 + \frac{1-\rho}{2} \|\mathbf{w}\|_2^2 \right]\]- $\rho = 1$: Lasso
- $\rho = 0$: Ridge
- $0 < \rho < 1$: 그룹 내 상관 특성을 함께 선택하면서 희소성도 확보
7. 비교 요약
| Ridge (L2) | Lasso (L1) | Elastic Net | |
|---|---|---|---|
| 패널티 | 계수 제곱합 (L2) | 계수 절댓값합 (L1) | L1 + L2 혼합 |
| 계수 = 0? | 아니오 | 예 | 예 (일부) |
| 특성 선택 | 불가 | 가능 | 가능 |
| 다중공선성 | 강건 | 취약 (하나만 선택) | 강건 |
| 닫힌 해 | 존재 | 없음 (iterative) | 없음 (iterative) |
| 주 용도 | 계수 안정화 | 희소 모델 | 균형 |
8. 실전 코드 (Python / sklearn)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import numpy as np
from sklearn.linear_model import Ridge, Lasso, ElasticNet, RidgeCV, LassoCV
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# 규제 전 스케일링은 필수
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Ridge
ridge = Ridge(alpha=1.0)
ridge.fit(X_train_scaled, y_train)
# Lasso
lasso = Lasso(alpha=0.1)
lasso.fit(X_train_scaled, y_train)
print("0인 계수 수:", np.sum(lasso.coef_ == 0))
# Elastic Net
enet = ElasticNet(alpha=0.1, l1_ratio=0.5)
enet.fit(X_train_scaled, y_train)
# 교차 검증으로 alpha 탐색
ridge_cv = RidgeCV(alphas=[0.01, 0.1, 1.0, 10.0], cv=5)
ridge_cv.fit(X_train_scaled, y_train)
print("최적 alpha:", ridge_cv.alpha_)
스케일링 주의: 규제는 계수의 크기에 직접 패널티를 주므로, 특성 간 단위가 다르면 결과가 왜곡됩니다. 반드시
StandardScaler로 정규화한 뒤 규제를 적용하세요.
계수 경로로 λ 효과 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from sklearn.linear_model import lasso_path
import numpy as np
import matplotlib.pyplot as plt
alphas = np.logspace(-3, 1, 100)
alphas_out, coefs, _ = lasso_path(X_train_scaled, y_train, alphas=alphas)
plt.figure(figsize=(8, 4))
plt.semilogx(alphas_out, coefs.T)
plt.xlabel("alpha (λ)")
plt.ylabel("계수 값")
plt.title("Lasso 계수 경로 — λ가 커질수록 계수가 순차적으로 0에 수렴")
plt.axhline(0, color='k', linewidth=0.5)
plt.gca().invert_xaxis()
plt.tight_layout()
plt.show()
λ가 작을 때 계수가 퍼져 있다가, 커질수록 차례로 0에 수렴합니다. 먼저 0이 되는 계수일수록 덜 중요한 특성입니다. 이 경로를 보면 어느 λ 구간에서 어떤 특성이 살아남는지 한눈에 파악할 수 있습니다.
9. 언제 무엇을 쓸까
| 상황 | 추천 |
|---|---|
| 모든 특성이 유의미하다고 생각될 때 | Ridge |
| 특성이 많고 일부만 관련 있을 것 같을 때 | Lasso |
| 특성 간 상관이 높고 희소성도 원할 때 | Elastic Net |
| 탐색 단계에서 잘 모를 때 | Elastic Net (범용) |
마치며
L1과 L2 규제는 단순히 “과적합을 막는 테크닉”을 넘어, 어떤 종류의 해를 선호하는가라는 사전 가정을 모델에 심는 행위입니다.
- L2 = 계수가 전체적으로 작기를 기대 → 수축
- L1 = 계수 대부분이 0이기를 기대 → 소거
베이즈 관점에서 이 사전 가정이 구체적으로 무엇인지는 베이지안 회귀와 MAP 포스팅에서 다룹니다.