Prophet — 예시·비교·앙상블·실전 전략 (2부)
모형 구조와 추정 원리는 1부에서 다뤘습니다. 이 글에서는 실제 예시 적용, ARIMA·ETS와의 비교, 앙상블 전략, 활용 판단 기준을 살펴봅니다.
9. Prophet 강점이 드러나는 예시 — Peyton Manning Wikipedia 조회수
Air Passengers처럼 단순한 월별 데이터보다, Prophet의 강점이 명확하게 드러나는 예시로 시작합니다. Peyton Manning의 Wikipedia 일별 페이지 조회수(2007–2016)입니다.1
이 데이터에는 Prophet이 잘 다루는 요소가 모두 들어 있습니다:
- 주간 계절성: 일요일(경기일) + 월요일(경기 다음날) 조회수 급등
- 연간 계절성: NFL 시즌(9월–2월) 정점, 비시즌(5월–8월) 저점
- 이벤트: Super Bowl 날 조회수 스파이크
- 추세 change points: 2011년 목 부상·수술, 2012년 덴버 브롱코스 이적, 2014년 터치다운 신기록 등 커리어 이벤트마다 기울기가 꺾임
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import pandas as pd
from prophet import Prophet
# 데이터: Prophet 공식 예시 (log-transformed Wikipedia pageviews)
df = pd.read_csv(
'https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv'
)
df['ds'] = pd.to_datetime(df['ds'])
train = df[df['ds'] < '2015-01-01']
test = df[df['ds'] >= '2015-01-01']
# Super Bowl 날짜를 holiday로 등록
super_bowls = pd.DataFrame({
'holiday': 'super_bowl',
'ds': pd.to_datetime([
'2008-02-03', '2009-02-01', '2010-02-07', '2011-02-06',
'2012-02-05', '2013-02-03', '2014-02-02', '2015-02-01', '2016-02-07'
]),
'lower_window': 0,
'upper_window': 1,
})
model = Prophet(
holidays=super_bowls,
yearly_seasonality=True,
weekly_seasonality=True,
daily_seasonality=False,
changepoint_prior_scale=0.05,
)
model.fit(train)
future = model.make_future_dataframe(periods=len(test), freq='D')
forecast = model.predict(future)
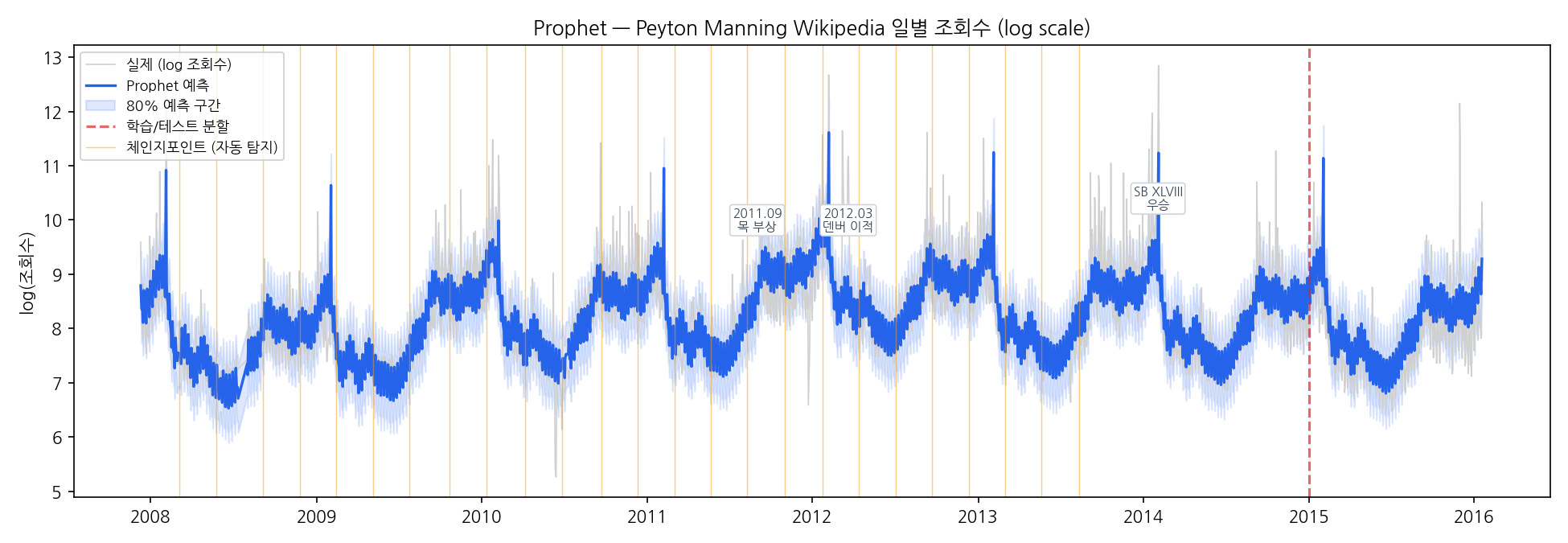
노란 수직선이 자동 탐지된 change points입니다. 2011년 목 부상(조회수 감소 시작), 2012년 덴버 이적(반등), 2013년 말–2014년 초 기록적 시즌(급등) 근방에 change point가 찍힙니다. 이 시점들은 모형에 명시적으로 알려주지 않았습니다.
컴포넌트 분해 결과를 보면 Prophet이 각 패턴을 어떻게 분리해냈는지 볼 수 있습니다:
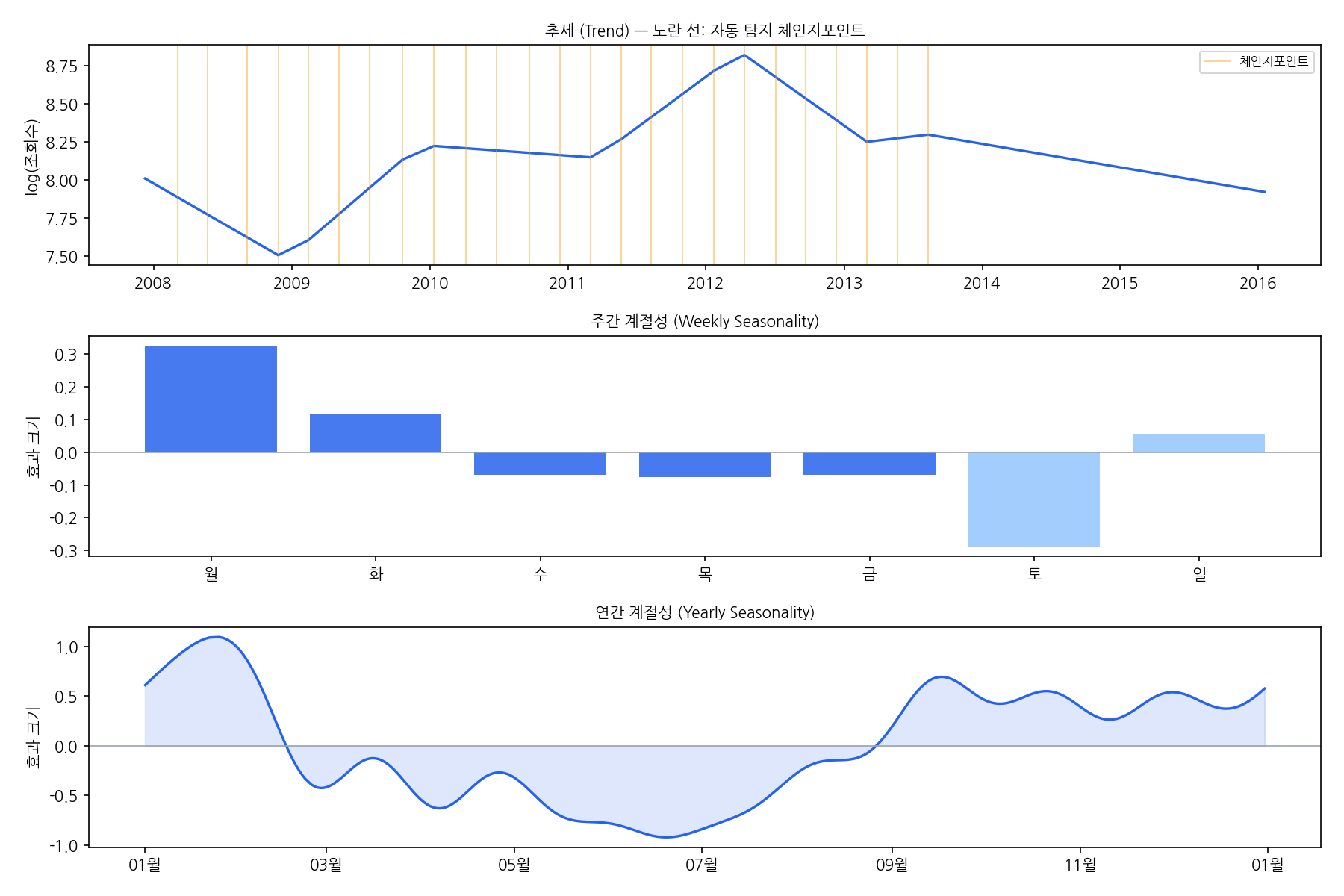
- 추세: 커리어 이벤트와 맞물려 기울기가 여러 번 꺾임
- 주간 계절성: 일요일(경기일) > 월요일 > 평일 > 토요일 순으로 명확한 패턴
- 연간 계절성: NFL 시즌 시작인 9월에 급등, 비시즌인 여름에 저점
ARIMA나 ETS는 이 세 가지를 동시에 분리해내기 어렵습니다. ARIMA는 주간 자기상관을 (7,d,q) 차분으로 간접 처리할 수 있지만 연간 계절성과 이벤트를 동시에 다루기 어렵고, ETS는 단일 계절 주기만 지원합니다.
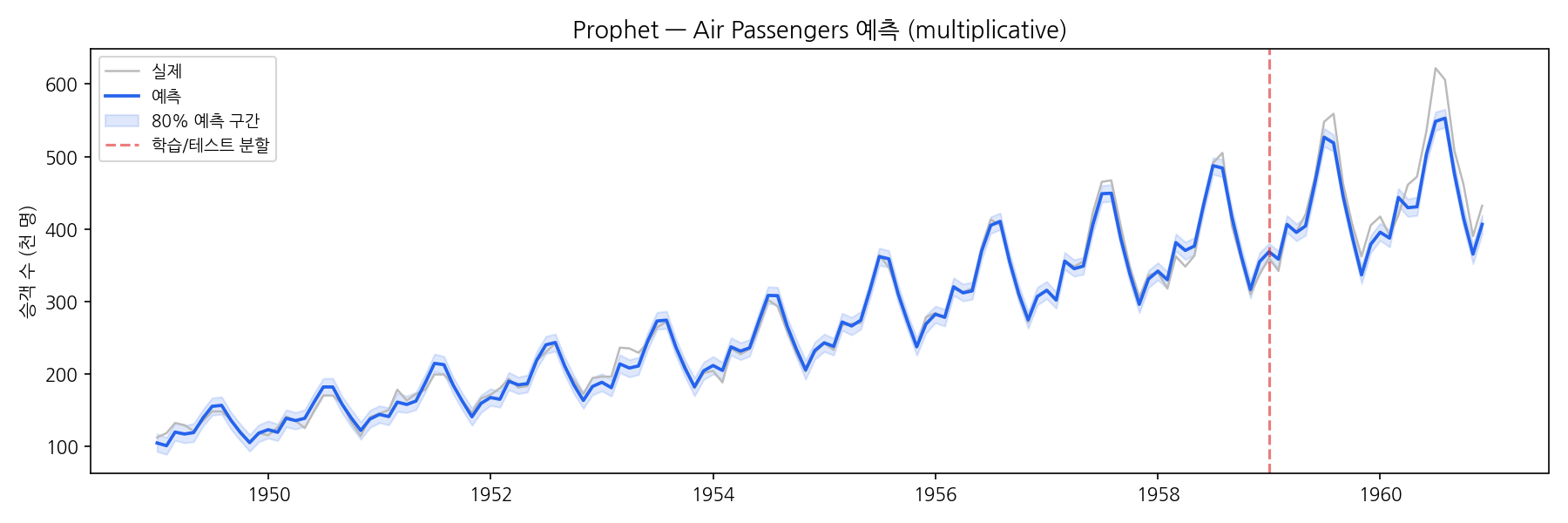
10. Air Passengers 적용 예시
이전 포스트들과 같은 데이터로 비교합니다. Air Passengers는 승법 계절성이 명확하므로 seasonality_mode='multiplicative'를 씁니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
import pandas as pd
import numpy as np
import statsmodels.api as sm
from prophet import Prophet
import matplotlib.pyplot as plt
# 데이터 준비
ap = sm.datasets.get_rdataset("AirPassengers", "datasets").data
df = pd.DataFrame({
'ds': pd.date_range('1949-01', periods=144, freq='MS'),
'y': ap['value'].values,
})
train = df[df['ds'] < '1959-01-01']
test = df[df['ds'] >= '1959-01-01']
# 모형 적합
model = Prophet(
seasonality_mode='multiplicative',
yearly_seasonality=True,
weekly_seasonality=False,
daily_seasonality=False,
changepoint_prior_scale=0.05,
)
model.fit(train)
# 예측
future = model.make_future_dataframe(periods=24, freq='MS')
forecast = model.predict(future)
# 예측 시각화
fig, ax = plt.subplots(figsize=(12, 4))
ax.plot(df['ds'], df['y'], color='lightgray', label='실제')
ax.plot(forecast['ds'], forecast['yhat'], label='예측', linewidth=1.8)
ax.fill_between(
forecast['ds'],
forecast['yhat_lower'],
forecast['yhat_upper'],
alpha=0.2, label='80% 예측 구간',
)
ax.axvline(pd.Timestamp('1959-01-01'), color='red', linestyle='--', alpha=0.5, label='학습/테스트 분할')
ax.legend()
ax.set_title('Prophet — Air Passengers 예측')
plt.tight_layout()
plt.savefig('assets/img/posts/fig_prophet_forecast.png', dpi=150)
plt.show()
1
2
3
4
5
# 컴포넌트 분해 시각화
fig = model.plot_components(forecast)
plt.tight_layout()
plt.savefig('assets/img/posts/fig_prophet_components.png', dpi=150)
plt.show()
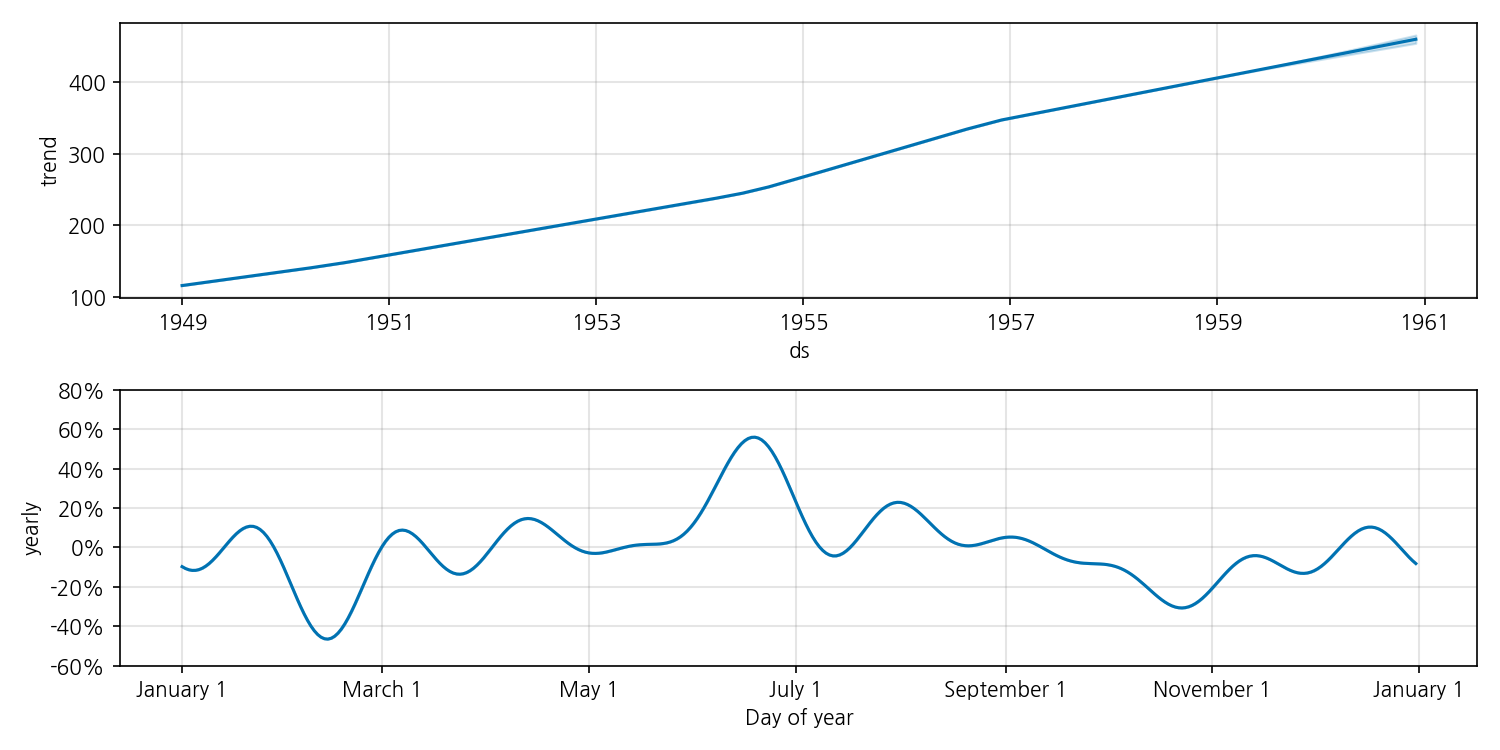
plot_components()는 추세, 연간 계절성을 분리해 보여줍니다. 추세 그래프에서 수직 점선으로 표시되는 자동 탐지 change points도 확인할 수 있습니다.
1
2
3
4
5
# 24개월 예측 MAPE
pred = forecast[forecast['ds'].isin(test['ds'])][['ds', 'yhat']]
merged = test.merge(pred, on='ds')
mape = np.mean(np.abs((merged['y'] - merged['yhat']) / merged['y'])) * 100
print(f"MAPE: {mape:.2f}%")
| 모형 | MAPE (24개월) |
|---|---|
| SARIMA(0,1,1)(0,1,1)₁₂ | 8.52% |
| Holt-Winters (수동) | 6.39% |
| ETS (자동) | ~6% |
| Prophet (multiplicative) | 5.35% |
Air Passengers는 이벤트·휴일 효과가 없는 단순한 교과서 데이터입니다. Prophet의 강점인 복수 계절성과 휴일 처리가 드러나지 않으므로 수치 비교보다 모형 구조 파악에 집중하는 것이 좋습니다.
11. ARIMA·ETS와의 비교
결정적 차이: 잔차 자기상관
ARIMA는 잔차 자기상관을 핵심으로 모델링합니다. ETS는 상태공간 구조에서 간접적으로 처리합니다. Prophet은 기본 관측 오차를 독립 오차로 두며 ARMA식 잔차 자기상관 구조를 포함하지 않습니다. 적합 후 잔차에 ACF를 그려 패턴이 남아 있으면 Prophet 단독으로는 포착하지 못하는 구조입니다.
왜 “$t$를 독립변수로 쓰는 회귀”이면 잔차 자기상관을 못 잡는가
Prophet의 예측 함수는 타임스탬프 $t$만 보고 예측값을 만듭니다:
\[\hat{y}(t) = g(t) + s(t) + h(t)\]이 함수는 어제 잔차가 얼마였는지, 그제 값이 얼마였는지 전혀 참조하지 않습니다. 반면 ARIMA(1,0,0)의 예측 함수는:
\[\hat{y}_t = \phi_1 y_{t-1} + \text{const}\]어제 관측값 $y_{t-1}$ 을 직접 입력으로 받습니다.
잔차 자기상관이 있다는 것은 예컨대 $\epsilon_t = 0.8\,\epsilon_{t-1} + \text{white noise}$ 같은 구조가 남아 있다는 뜻입니다. 이 패턴을 활용하려면 모형이 “어제 잔차가 얼마였는지”를 알아야 합니다. Prophet은 $t$만 입력으로 받으므로 그 경로 자체가 없습니다. 잔차에 패턴이 남아 있어도 다음 예측에 반영할 방법이 없습니다.
| 예측 함수의 입력 | 잔차 패턴 활용 | |
|---|---|---|
| ARIMA | $y_{t-1},\, y_{t-2},\, \epsilon_{t-1}, \ldots$ | 가능 |
| Prophet | $t$ (타임스탬프) | 불가 |
이건 Prophet만의 문제가 아닙니다. 시간을 독립변수로 쓰는 회귀는 모두 같은 한계를 가집니다. 단순 선형 회귀 $y = \beta_0 + \beta_1 t + \epsilon$도 잔차에 자기상관이 있으면 예측이 비효율적(inefficient)입니다. ARIMA는 그 남은 패턴까지 쓰는 모형입니다.
계절성 표현
기본 SARIMA는 단일 계절 차분, 기본 ETS는 단일 계절 컴포넌트를 중심으로 다루는 반면, Prophet은 복수 계절 주기를 동시에 처리합니다. 물론 SARIMAX에 Fourier term을 넣거나 TBATS/MSTL 같은 확장을 쓰면 다른 접근에서도 복수 계절성을 다룰 수 있습니다.
동치 관계
일부 선형 additive ETS와 ARIMA 사이에는 예측식 수준의 연결이 있습니다(예: 일정 조건하에서 SES = ARIMA(0,1,1), Holt’s = ARIMA(0,2,2)). Prophet과 이들 사이에는 공식적인 동치 관계가 없습니다. 같은 데이터를 다루지만 패러다임이 다른 모형입니다.
ARIMA / ETS
- 과거 $y$ 값의 점화식
- 잔차 자기상관 모델링 (ARIMA)
- 단일 계절 주기
- AIC/BIC 자동 선택
- 결측·불규칙 간격에 약함
Prophet
- 시간 $t$를 입력으로 받는 회귀
- 잔차 자기상관 미처리
- 복수 계절 주기 동시 지원
- CV 기반 수동 튜닝
- 결측·불규칙 간격에 강함
12. Prophet이 다루지 않는 영역
| 영역 | 대안 |
|---|---|
| 잔차 자기상관 | ARIMA on residuals |
| 조건부 이분산·변동성 클러스터링 | GARCH |
| 다변량 의존성 | VAR, VARMA |
| 비가우시안 오차 | GLM 계열 시계열 |
| 계절 패턴 자체의 구조적 변화 | STL + 동적 모형 |
실전에서 가장 자주 마주치는 한계는 잔차 자기상관입니다. 이는 Prophet과 ARIMA를 결합해 해결할 수 있습니다.
13. 앙상블 전략
Prophet + ARIMA on residuals
점예측 앙상블로는 간단하지만, Prophet과 ARIMA 잔차 모델의 예측 불확실성을 어떻게 결합할지는 별도로 다뤄야 합니다. 따라서 아래 방식은 우선 점예측 개선 아이디어로 이해하는 편이 안전합니다.
Prophet이 추세·계절·이벤트를 제거한 뒤 남은 잔차를 ARIMA로 추가 모델링합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
from statsmodels.tsa.arima.model import ARIMA
# 1단계: Prophet 학습 구간 적합값
forecast_train = forecast[forecast['ds'].isin(train['ds'])]
residuals = train['y'].values - forecast_train['yhat'].values
# 2단계: 잔차를 ARIMA로 모델링
arima_res = ARIMA(residuals, order=(1, 0, 1)).fit()
arima_fcast = arima_res.forecast(steps=24)
# 3단계: Prophet 예측 + ARIMA 잔차 예측 합산
forecast_test = forecast[forecast['ds'].isin(test['ds'])]['yhat'].values
final = forecast_test + arima_fcast
Prophet + LightGBM
Prophet의 컴포넌트 분해 결과($\hat{g}$, $\hat{s}$, $\hat{h}$)를 피처로 ML 모형에 투입하는 패턴입니다. Kaggle 시계열 대회 상위권 솔루션에 자주 등장합니다.
단순 평균 앙상블
1
final = (prophet_forecast + ets_forecast + arima_forecast) / 3
모형별 가정이 달라 각자 포착하는 패턴이 다르기 때문에, 단순 평균만으로도 개별 모형보다 안정적인 예측이 나오는 경우가 많습니다.
14. 언제 Prophet을 쓸까
잘 맞는 경우:
- 1년 이상의 일별 또는 시간별 데이터
- 연간·주간·일간이 겹치는 복수 계절성
- 연휴·프로모션 등 알려진 이벤트 효과
- 추세 꺾임이 발생한 이력이 있는 데이터
- 결측치나 불규칙 시간 간격
주의가 필요한 경우:
- 금융 수익률처럼 자기상관이 지배적인 데이터
- 학습 데이터가 수십 개 수준으로 짧은 경우 (change point 탐지 불안정)
- 변동성 예측이 목적인 경우 (Prophet은 평균 예측만 제공)
- 다변량 인과 관계가 핵심인 경우
이전 포스트들의 흐름과 연결 지으면: ARIMA는 자기상관 구조를, ETS는 지수가중 분해를, Prophet은 회귀 분해를 핵심 아이디어로 삼습니다. 세 접근법은 서로 경쟁하기도 하지만 각자가 잘 다루는 시계열의 결이 다릅니다. 앙상블을 통해 보완적으로 쓰는 것이 실전에서 더 일반적입니다.
참고문헌
- Taylor, S. J., & Letham, B. (2018). Forecasting at scale. The American Statistician, 72(1), 37–45. DOI: 10.1080/00031305.2017.1380080
- Carpenter, B., Gelman, A., Hoffman, M. D., Lee, D., Goodrich, B., Betancourt, M., Brubaker, M., Guo, J., Li, P., & Riddell, A. (2017). Stan: A probabilistic programming language. Journal of Statistical Software, 76(1), 1–32.
- Hyndman, R. J., & Athanasopoulos, G. (2021). Forecasting: Principles and Practice (3rd ed.). OTexts.
AI의 도움을 받아 작성되었으며 최대한 레퍼런스를 밝히려 노력했으나 오류가 있을 수 있으니 정확한 정보를 다시 한번 확인하시기 바랍니다.
Peyton Manning Wikipedia 조회수 데이터는 Prophet 공식 GitHub 예시 데이터셋입니다.
y값은 자연로그 변환된 조회수입니다. ↩︎