데이터 뒤에는 모수가 있다 — 모수 추정의 발상부터 시계열까지
본격적으로 정상성을 다루기 전에, 한 가지 짚고 넘어갈 것이 있습니다. 정상성이니, 평균이니, 분산이니 하는 이야기는 사실 “데이터 뒤에 어떤 모수(parameter)가 있고, 우리는 그걸 추정한다” 는 사고틀을 깔고 있어야 자연스럽게 들립니다.
ML/AI를 하시던 분들에게는 이 사고틀이 살짝 낯설 수 있습니다. 보통 ML에서는 “데이터를 입력하면 모델이 패턴을 학습한다”는 흐름으로 사고하지요. 전통적 통계학은 그보다 모수와 불확실성 평가를 더 명시적으로 다루는 경향이 있습니다. 물론 ML도 확률모형과 모수 추정을 사용하고, 통계학도 예측을 합니다. 다만 여기서는 모수가 먼저 있고, 그 모수가 데이터를 만들어 낸다는 생성 관점에서 출발해 보겠습니다. 이 관점이 자리잡혀야 ARIMA의 $\phi, \theta$니, 가능도(likelihood)니 하는 이야기가 갑자기 튀어나오는 느낌을 받지 않습니다.
이번 글에서는 정규분포에서 출발해서 모수 추정의 발상을 따라간 다음, 시계열로 가는 다리까지 놓아 보겠습니다.
1. 시작하기 전에 — 랜덤 프로세스라는 큰 그림
본격적으로 들어가기 전에 한 가지 용어만 미리 깔겠습니다. 랜덤 프로세스(stochastic process, 확률과정) 입니다.1
거창해 보이지만 직관은 단순합니다. 시간(혹은 인덱스)에 따라 늘어선 확률변수들의 모음입니다. 즉 시계열 $\lbrace X_1, X_2, X_3, \ldots \rbrace$의 각 $X_t$는 단순한 숫자가 아니라 확률변수이고, 우리가 손에 쥔 데이터는 그 확률변수들이 한 번 “주사위를 굴려서” 나온 결과물입니다.
이게 왜 중요하냐면, 시계열을 분석한다는 행위가 사실은 눈에 보이는 데이터(관측값) 뒤에 있는, 눈에 안 보이는 데이터 생성기(확률과정)를 추정하는 작업이라는 뜻이기 때문입니다. 이 사고틀을 잡고 가면 뒤에 나오는 모든 이야기가 한결 명확해집니다.
2. 정규분포부터 시작 — 모수란 무엇인가
가장 친숙한 정규분포 $\mathcal{N}(\mu, \sigma^2)$를 떠올려 봅시다. 이 표기에서 $\mu$(평균)와 $\sigma^2$(분산)이 모수(parameter) 입니다. 모수란 분포의 모양을 결정하는 숫자들입니다. $\mu$가 어디 있느냐에 따라 종 모양이 좌우로 움직이고, $\sigma^2$가 얼마냐에 따라 종이 뾰족하거나 퍼집니다.
여기서 통계의 핵심 사고를 받아들이셔야 합니다. 모수가 먼저 정해져 있고, 그 모수가 데이터를 생성합니다. 같은 $\mathcal{N}(170, 36)$이라도 표본을 뽑을 때마다 결과는 조금씩 다릅니다.
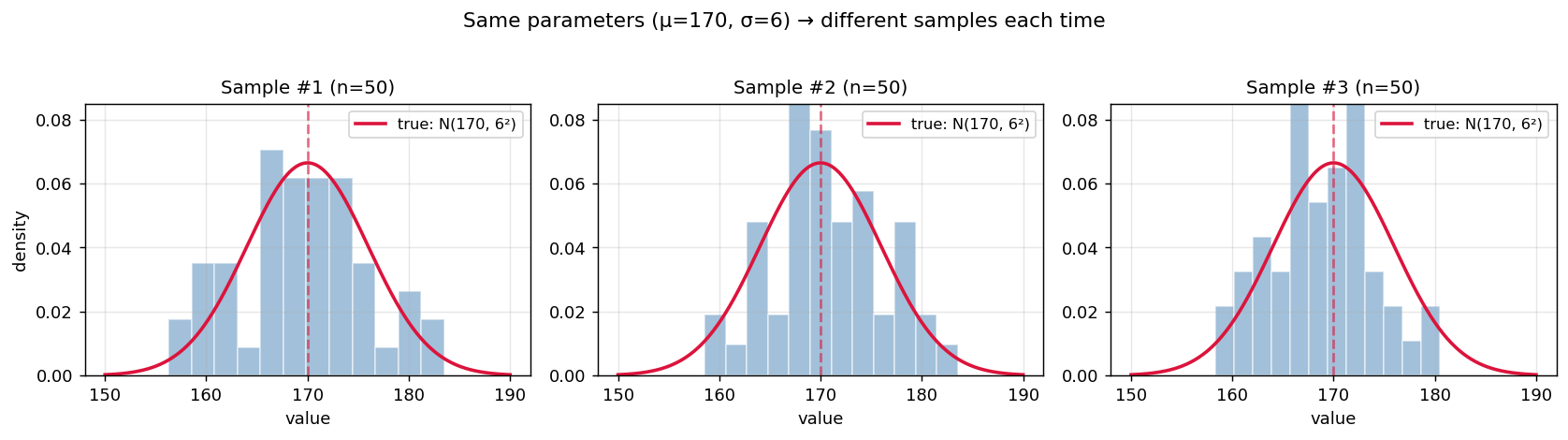
세 그림 모두 동일한 모수 $\mu=170, \sigma=6$에서 뽑은 50개짜리 표본입니다. 데이터의 모양은 매번 다르지만, 그 뒤에 있는 “데이터 생성기”는 같은 정규분포 한 개입니다. 통계학은 이 눈에 안 보이는 생성기에 관심이 있습니다.
⚠️ 헷갈리기 쉬운 용어: 모수(parameter) 와 매개변수(parameter) 는 영어로 같은 단어입니다. 다만 한국어 통계 문헌에서는 “모집단의 미지수”라는 의미로 모수를, ML/딥러닝에서는 “학습되는 가중치” 의미로 매개변수를 주로 씁니다. 이 글에서는 통계 용법을 따라 모수로 통일합니다.
3. 추정의 발상 — 데이터를 보고 모수를 거꾸로 찾기
자, 그런데 현실에서 우리는 모수를 모릅니다. 우리가 가진 건 데이터뿐입니다. 그래서 거꾸로 가야 합니다. 데이터를 보고 그 뒤에 있을 법한 모수를 추측하는 작업, 이게 바로 모수 추정(parameter estimation) 입니다.
ML 식으로 말하자면 “추론(inference)”과 비슷한 자리에 있지만, 결정적으로 다른 점이 있습니다.
- ML에서는 모델 파라미터를 학습한 뒤, 새로운 입력 $x$에 대해 출력 $y$를 예측합니다.
- 통계에서는 모델 파라미터(모수) 자체가 관심의 대상입니다. 추정의 결과로 얻는 것이 곧 답입니다.
물론 시계열 예측에서는 결국 모수를 추정한 뒤 미래 값을 예측하니까 두 흐름이 합쳐지지만, 출발점의 사고는 다릅니다.
4. 가능도(Likelihood) — “이 모수가 이 데이터를 얼마나 그럴싸하게 설명하는가”
추정에서 가장 핵심적인 도구가 가능도(likelihood) 입니다. 이름이 무섭게 들리지만, 정의는 한 줄입니다.
가능도란, 어떤 모수 값이 우리가 관찰한 데이터를 얼마나 그럴듯하게 설명하는지를 나타내는 숫자입니다.
기호로는 $L(\boldsymbol{\theta} \mid \text{data})$로 씁니다.2 데이터를 고정해 두고, 모수 $\boldsymbol{\theta}$를 이리저리 바꿔 가면서 “이 모수면 이 데이터가 나올 만하다 / 이 모수면 이 데이터가 거의 안 나올 것 같다”를 점수로 매기는 함수입니다.
직관적으로 봅시다. 키 데이터 30개를 관측했다고 합시다. 분산은 $\sigma=6$으로 고정해 두고 $\mu$만 바꿔 보면:
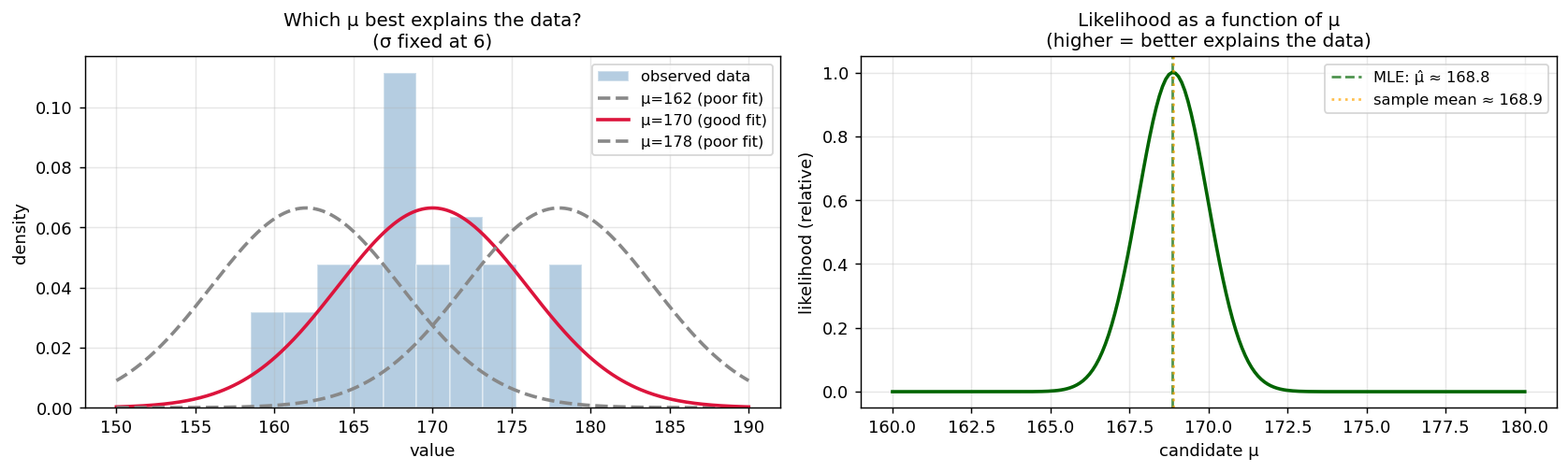
- 왼쪽 그림: $\mu=162$나 $\mu=178$인 정규분포는 우리 데이터의 위치와 안 맞습니다. $\mu=170$ 부근이 데이터를 가장 잘 덮고 있습니다.
- 오른쪽 그림: 모든 $\mu$ 값에 대해 “이 $\mu$가 데이터를 얼마나 잘 설명하는가”를 점수로 그린 곡선입니다. 이 곡선의 꼭대기가 바로 데이터를 가장 잘 설명하는 $\mu$ 값이고, 이걸 최대가능도추정량(MLE; Maximum Likelihood Estimator) 이라고 부릅니다.3
여기까지가 큰 그림입니다. 수식 유도는 다른 포스팅에서 다루기로 하고, “가능도란 모수의 그럴싸함을 재는 점수이고, MLE는 그 점수를 최대화하는 모수다” 라는 직관만 잡으시면 충분합니다.
4.1 잠깐, 사실 ML을 하시던 분들은 이미 매번 MLE를 하고 있었습니다
여기서 ML/딥러닝 배경의 독자라면 “그래서 그게 내가 매일 짜는 학습 코드와 무슨 상관이지?”라는 의문이 들 수 있습니다. 결론부터 말하면, 이미 매번 MLE를 수행하고 계셨습니다. 다만 그걸 “MLE”라고 부르지 않고 “loss 최소화”라고 불렀을 뿐입니다.
이미지 분류 모델 학습을 떠올려 봅시다. 입력 $x$(이미지), 라벨 $y$(클래스), 모델 파라미터 $\boldsymbol{\theta}$(CNN과 FC layer의 모든 가중치). 학습 후 추론 단계에서 마지막에 softmax를 통과시키지요. 이 softmax 출력값이 사실 다음을 의미합니다.
\[p(y \mid x; \boldsymbol{\theta}) = \text{모델이 추정한, } x\text{가 클래스 } y\text{일 확률}\]즉 분류 모델은 본질적으로 조건부 확률을 모델링하는 함수입니다. 그러면 학습 데이터 $\lbrace (x_i, y_i) \rbrace_{i=1}^{N}$에 MLE의 발상을 그대로 적용해 봅시다.
\[\hat{\boldsymbol{\theta}} = \arg\max_{\boldsymbol{\theta}} \prod_{i=1}^{N} p(y_i \mid x_i; \boldsymbol{\theta})\]곱셈은 다루기 어려우니 로그를 취하고, 최적화 관행에 맞춰 부호를 뒤집으면:
\[\hat{\boldsymbol{\theta}} = \arg\min_{\boldsymbol{\theta}} \left[ - \sum_{i=1}^{N} \log p(y_i \mid x_i; \boldsymbol{\theta}) \right]\]대괄호 안의 식이 표준 cross-entropy loss입니다. 독립 표본을 가정하고, 정규화·label smoothing·class weight 같은 변형이 없을 때 PyTorch의 nn.CrossEntropyLoss()가 내부적으로 계산하는 값이 바로 이것이지요. 즉 매번 짜시는 다음 한 줄짜리 코드가:
1
loss = nn.CrossEntropyLoss()(logits, labels)
이론적으로 풀면 “음의 로그가능도(negative log-likelihood, NLL)” 입니다. 그리고 SGD/Adam으로 이걸 최소화하는 학습 루프 전체가 곧 MLE 추정 절차입니다. 다만 weight decay 같은 정규화 항이 붙으면 달라집니다. PyTorch에서 weight_decay=λ를 주면 실제 최소화되는 목적함수는 다음과 같습니다.
이 형태는 MAP(Maximum A Posteriori) 추정과 정확히 같습니다. MAP는 원래 사후분포를 최대화하는 문제입니다.
\[\hat{\boldsymbol{\theta}}_{\text{MAP}} = \arg\max_{\boldsymbol{\theta}} \left[ \log p(\text{data} \mid \boldsymbol{\theta}) + \log p(\boldsymbol{\theta}) \right]\]경사하강법에 맞게 부호를 뒤집어 최소화 문제로 바꾸면:
\[\hat{\boldsymbol{\theta}}_{\text{MAP}} = \arg\min_{\boldsymbol{\theta}} \left[ \underbrace{-\log p(\text{data} \mid \boldsymbol{\theta})}_{\text{NLL}} \underbrace{- \log p(\boldsymbol{\theta})}_{\text{prior 항}} \right]\]사전분포로 $\boldsymbol{\theta} \sim \mathcal{N}(0, \sigma^2 I)$를 가정하면 $\log p(\boldsymbol{\theta}) \propto -|\boldsymbol{\theta}|^2/(2\sigma^2)$이므로, $-\log p(\boldsymbol{\theta}) \propto +\lambda|\boldsymbol{\theta}|^2$이 됩니다. 가우시안 prior의 log가 음수이고, 그걸 부호 반전하면 양수 패널티가 되어 NLL과 덧셈으로 합쳐집니다.
\[\hat{\boldsymbol{\theta}}_{\text{MAP}} = \arg\min_{\boldsymbol{\theta}} \left[ \text{NLL}(\boldsymbol{\theta}) + \lambda \|\boldsymbol{\theta}\|^2 \right]\]weight decay의 $\lambda$는 $1/(2\sigma^2)$에 해당하고, $\lambda$를 키울수록 “가중치가 0에 가까울 것”이라는 사전 믿음을 강하게 반영합니다. $\lambda = 0$이면 사전분포가 없는 순수 MLE로 돌아갑니다. 가우시안 대신 라플라스 사전분포를 쓰면 L1 규제(Lasso)가 됩니다. 전체 유도는 베이지안 회귀와 MAP와 L1·L2 규제에서 다룹니다.
이 연결은 cross-entropy에만 해당하지 않습니다. ML에서 자주 쓰는 loss들은 대부분 특정 확률모형의 NLL입니다.
| Loss | 출력 분포 가정 | MLE 해석 |
|---|---|---|
| Cross-entropy | $y \mid x \sim \text{Categorical}(\text{softmax}(f(x; \boldsymbol{\theta})))$ | 다중 분류의 MLE |
| Binary cross-entropy | $y \mid x \sim \text{Bernoulli}(f(x; \boldsymbol{\theta}))$ | 이진 분류의 MLE |
| MSE (회귀) | $y \mid x \sim \mathcal{N}(f(x; \boldsymbol{\theta}), \sigma^2)$ | 가우시안 가정 하의 MLE |
물론 모든 loss가 MLE인 것은 아닙니다 — hinge loss나 contrastive loss처럼 명시적 확률모형이 깔리지 않은 loss도 있고, L1 정규화는 베이즈 관점의 MAP 추정으로 해석되기도 합니다. 하지만 “loss 최소화의 상당 부분은 사실 MLE의 다른 이름” 이라는 사실은 알아둘 가치가 있습니다.4
이 다리가 놓이고 나면 시계열로 가는 길이 한결 자연스럽습니다. 분류는 입력 $x$를 조건으로 한 $p(y \mid x; \boldsymbol{\theta})$의 곱을 최대화했지요. 시계열은 과거 값들을 조건으로 합니다. 다음 절에서 그 차이를 보겠습니다.
5. 시계열로 — 조건부 가능도라는 다리
여기까지는 i.i.d.(독립항등분포) 데이터, 즉 표본들이 서로 독립인 경우를 가정했습니다. 하지만 시계열은 표본들이 서로 얽혀 있습니다. 오늘 값은 어제 값에 의존하지요. 그래서 가능도의 형태를 살짝 바꿔야 합니다.
시계열에서는 한 시점의 값 $X_t$가 과거의 값들에 의존한다고 모형화합니다. 그래서 조건부 분포를 씁니다.
\[p(X_t \mid X_{t-1}, X_{t-2}, \ldots\, ; \boldsymbol{\theta})\]읽는 방법은 이렇습니다. “모수 $\boldsymbol{\theta}$가 주어진 상태에서, 과거 값 $X_{t-1}, X_{t-2}, \ldots$를 알고 있을 때, 현재 값 $X_t$가 어떻게 분포하느냐.”
전체 시계열에 대한 가능도는 이 조건부 분포들을 시간 순서대로 곱한 형태가 됩니다. 이걸 조건부 가능도(conditional likelihood) 라고 부릅니다. 입문적으로는 이 관점만으로도 충분하지만, 실제 소프트웨어는 exact likelihood나 상태공간/Kalman filter 기반 likelihood를 쓰기도 합니다. 식 자체는 다음 포스팅에서 ARIMA를 다룰 때 본격적으로 보여 드리겠습니다. 지금은 큰 그림만 받아들이시면 됩니다.
시계열 모수 추정의 핵심:
- 데이터 뒤에 확률과정이 있고, 그 과정은 모수로 기술된다.
- 가능도는 “이 모수가 이 시계열을 얼마나 그럴싸하게 설명하는가”의 점수다.
- 시계열에서는 시점 간 의존성을 반영해 조건부 가능도 형태로 점수를 매긴다.
- 그 점수를 최대화하는 모수를 추정값으로 삼는다.
6. 부록 — 베이즈 관점은 어떻게 다른가
여기까지 설명한 흐름은 빈도주의(frequentist) 관점 입니다. 모수 $\boldsymbol{\theta}$를 “모르지만 정해져 있는 어떤 숫자”로 봅니다. 데이터를 보고 점추정값을 하나 뽑는 것이 목표입니다.
반면 베이즈주의(Bayesian) 관점에서는 모수 자체를 확률변수로 봅니다. 데이터를 본 뒤 모수가 어떤 분포를 따르는지를 통째로 추론합니다. 베이즈 정리로 표현하면 이런 모양입니다.
\[p(\boldsymbol{\theta} \mid \text{data}) \propto p(\text{data} \mid \boldsymbol{\theta}) \cdot p(\boldsymbol{\theta})\]오른쪽 첫 번째 항이 가능도, 두 번째 항이 사전분포(prior) 입니다. 즉 가능도 위에 “모수가 미리 어떤 값일 거라고 믿었는지”를 곱해서, 데이터를 본 후의 믿음을 갱신하는 구조입니다. 베이지안 시계열 모형(예: PyMC, Stan 기반의 베이지안 ARIMA, 베이지안 구조시계열 등)은 이 관점을 따릅니다. 본격적인 이야기는 베이지안 회귀와 MAP 포스팅에서 다룹니다.
7. 마무리 — 다음 포스팅 예고
이번 글에서는 “데이터 뒤에 모수가 있고, 가능도라는 점수를 통해 그 모수를 추정한다”는 큰 사고틀을 잡았습니다. 시계열은 여기에 시점 간 의존성이 추가될 뿐입니다.
다음 포스팅에서는 이 사고틀을 가지고 “내 데이터가 정상인지 아닌지를 어떻게 검정하는가” 로 넘어가겠습니다. ADF 검정과 KPSS 검정을 다룰 예정입니다 — 두 검정은 귀무가설이 서로 반대라서 같이 쓰면 진단이 한결 견고해집니다.
참고문헌
- Brockwell, P. J., & Davis, R. A. (2016). Introduction to Time Series and Forecasting (3rd ed.). Springer.
- Casella, G., & Berger, R. L. (2002). Statistical Inference (2nd ed.). Duxbury.
- Hamilton, J. D. (1994). Time Series Analysis. Princeton University Press.
- Murphy, K. P. (2022). Probabilistic Machine Learning: An Introduction. MIT Press.
AI의 도움을 받아 작성되었으며 최대한 레퍼런스를 밝히려 노력했으나 오류가 있을 수 있으니 정확한 정보를 다시 한번 확인하시기 바랍니다.
정확한 수학적 정의는 “확률공간 $(\Omega, \mathcal{F}, P)$ 위에서 정의된, 인덱스 집합 $T$로 매개되는 확률변수들의 모임 $\lbrace X_t : t \in T \rbrace$”입니다. 시계열은 보통 $T = \mathbb{Z}$나 $T = \lbrace 1, 2, \ldots \rbrace$ 같은 이산적인 시간 인덱스를 사용합니다. 자세한 논의는 Brockwell & Davis(2016) Ch. 1 참고. ↩︎
가능도와 확률밀도의 관계: 수식상으로는 $L(\boldsymbol{\theta} \mid x) = p(x \mid \boldsymbol{\theta})$로 같은 함수입니다. 다만 보는 관점이 다릅니다. 확률밀도는 $\boldsymbol{\theta}$를 고정하고 $x$의 함수로 보고, 가능도는 $x$를 고정하고 $\boldsymbol{\theta}$의 함수로 봅니다. 그래서 가능도는 확률이 아닙니다(적분해도 1이 안 됩니다). ↩︎
MLE의 통계적 성질(일치성, 점근정규성, 효율성)에 대한 엄밀한 논의는 Casella & Berger(2002) Statistical Inference 7장이 표준 레퍼런스입니다. ↩︎
ML에서 흔히 쓰는 loss들과 확률모형의 대응 관계는 Murphy(2022) Probabilistic Machine Learning: An Introduction 의 4장 “Statistics”에 잘 정리되어 있습니다. 정규화 항(L1/L2)을 사전분포의 NLL로 해석하는 베이즈 MAP 관점은 L1·L2 규제와 베이지안 회귀와 MAP 포스팅에서 직접 다룹니다. ↩︎