베이지안 회귀와 MAP: L1·L2 규제는 왜 사전 분포인가
서론
L1·L2 규제 포스팅의 마지막에 이런 말을 남겼습니다.
L2 = 가우시안 사전 분포, L1 = 라플라스 사전 분포. 베이즈 관점에서 규제는 MAP 추정과 동치다.
이 포스팅에서는 그 문장이 왜 성립하는지 따져봅니다.
1. 빈도주의 vs 베이지안
빈도주의: 파라미터 $\mathbf{w}$는 고정된 미지의 상수입니다. 데이터로부터 그 값을 추정합니다. OLS(최소제곱법, Ordinary Least Squares), MLE(최대우도추정, Maximum Likelihood Estimation)가 여기에 해당합니다.
베이지안: 파라미터 $\mathbf{w}$ 자체가 확률 변수입니다. 데이터를 보기 전에도 $\mathbf{w}$에 대한 믿음(사전 분포, prior)이 있고, 데이터를 본 뒤 그 믿음을 업데이트한 것이 사후 분포(posterior)입니다.
베이즈 정리로 쓰면:
\[\underbrace{p(\mathbf{w} \mid X, \mathbf{y})}_{\text{사후(posterior)}} \;\propto\; \underbrace{p(\mathbf{y} \mid X, \mathbf{w})}_{\text{가능도(likelihood)}} \;\times\; \underbrace{p(\mathbf{w})}_{\text{사전(prior)}}\]| 사전 분포 | 사후 분포 | 최대화 대상 | |
|---|---|---|---|
| MLE | 없음 | 없음 | 가능도 |
| MAP | 있음 | 있음 (최빈값만 사용) | 사후 분포 |
MLE에 사전 분포를 하나 추가하면 MAP가 됩니다.
2. 선형 회귀에서 MLE = OLS
잡음이 가우시안이면, 로그 가능도를 최대화하는 것이 RSS(잔차제곱합, Residual Sum of Squares)를 최소화하는 것과 같습니다.
\[\log p(\mathbf{y} \mid X, \mathbf{w}) = -\frac{1}{2\sigma^2} \underbrace{\sum_{i=1}^n (y_i - \mathbf{w}^\top \mathbf{x}_i)^2}_{\text{RSS}} + \text{const}\]로그 가능도 최대화 = RSS 최소화 = OLS
3. MAP 추정 — 사전 분포를 더하면 규제가 된다
MAP는 사후 분포를 최대화합니다. 로그를 취하면:
\[\hat{\mathbf{w}}_{\text{MAP}} = \arg\max_{\mathbf{w}}\;\bigl[\log p(\mathbf{y} \mid X, \mathbf{w}) + \log p(\mathbf{w})\bigr]\]2절의 로그 가능도를 대입하고, 최대화를 최소화로 바꾸면:
\[\hat{\mathbf{w}}_{\text{MAP}} = \arg\min_{\mathbf{w}}\;\left[ \text{RSS} \;-\; 2\sigma^2 \log p(\mathbf{w}) \right]\]$-2\sigma^2 \log p(\mathbf{w})$ 항이 바로 규제 패널티입니다.
사전 분포 $p(\mathbf{w})$의 형태에 따라 패널티의 모양이 결정됩니다.
4. L2 규제 = 가우시안 사전 분포
계수들이 평균 0, 분산 $\tau^2$인 정규분포를 따른다고 가정하면:
\[\log p(\mathbf{w}) = -\frac{1}{2\tau^2} \sum_{j=1}^p w_j^2 + \text{const}\]MAP 목적함수에 대입하면 ($\lambda = \sigma^2 / \tau^2$):
\[\hat{\mathbf{w}}_{\text{MAP}} = \arg\min_{\mathbf{w}} \left[ \text{RSS} + \lambda \sum_{j=1}^p w_j^2 \right] = \hat{\mathbf{w}}_{\text{Ridge}}\]가우시안은 $w=0$에서 부드럽게 정점을 찍습니다. $-\log p(w) \propto w^2$인 포물선이므로, 계수를 0 근방으로 수축시키되 정확히 0으로 만들지는 못합니다.
5. L1 규제 = 라플라스 사전 분포
계수들이 위치 모수 0, 척도 모수 $b$인 라플라스 분포를 따른다고 가정하면:
\[\log p(\mathbf{w}) = -\frac{1}{b} \sum_{j=1}^p |w_j| + \text{const}\]MAP 목적함수에 대입하면 ($\lambda = 2\sigma^2 / b$):
\[\hat{\mathbf{w}}_{\text{MAP}} = \arg\min_{\mathbf{w}} \left[ \text{RSS} + \lambda \sum_{j=1}^p |w_j| \right] = \hat{\mathbf{w}}_{\text{Lasso}}\]라플라스는 $w=0$에서 뾰족한 꼭짓점을 가집니다. $-\log p(w) \propto \lvert w \rvert$인 V자이므로, 최적화가 $w=0$에 붙어버리는 현상이 발생합니다. 이것이 Lasso가 계수를 정확히 0으로 만드는 이유입니다.
라플라스 분포는 어떤 분포인가
확률밀도함수는 위치 모수 $\mu$, 척도 모수 $b$에 대해 다음과 같습니다.
\[p(x) = \frac{1}{2b} \exp\!\left( -\frac{\lvert x - \mu \rvert}{b} \right)\]지수가 $(x-\mu)^2$ 대신 $\lvert x-\mu \rvert$라는 점이 가우시안과의 유일한 차이입니다. 그런데 이 작은 차이에서 특성 두 가지가 갈립니다.
- 뾰족한 정점: 중심에서 미분이 불연속이라 꼭짓점이 뾰족합니다. → 사전 분포로 쓰면 희소성(sparsity)을 유도 (계수를 정확히 0으로).
- 두꺼운 꼬리: 꼬리가 $e^{-\lvert x \rvert}$로 감소해 가우시안($e^{-x^2}$)보다 천천히 줄어듭니다. → 중심에서 멀리 떨어진 값(이상치)에 관대합니다.
또한 위치 모수의 최대우도추정치가 가우시안은 평균인 반면 라플라스는 중앙값입니다. 중앙값이 이상치에 강건한 것과 같은 이유로, 라플라스 가정은 곧 이상치에 강건한 모델로 이어집니다.
잘 쓰이는가
“가우시안만큼 자주 쓰이지는 않는다”는 직관은 대체로 맞습니다. 기본 가정·오차 모델로는 여전히 가우시안이 압도적입니다. 다만 라플라스는 특정 목적이 분명할 때 골라 쓰는 전문 분포에 가깝고, 다음 영역에서는 오히려 표준입니다.
- 희소 모델링: Lasso·Bayesian Lasso 등 “많은 계수를 0으로” 보내고 싶을 때의 사전 분포.
- 강건 회귀: 오차를 라플라스로 가정하면 L1 손실(최소절대편차, 중앙값 회귀)이 되어 이상치에 강건.
- 차분 프라이버시(differential privacy): 쿼리 결과에 라플라스 노이즈를 더하는 Laplace mechanism이 핵심 기법.
- 신호·이미지 처리, 금융: 희소 표현이나 가우시안보다 두꺼운 꼬리(급변·극단값)를 모델링할 때.
기본 선택지는 아니지만, 희소성·강건성·프라이버시가 걸린 문제라면 가우시안 대신 라플라스를 꺼내 들 만합니다.
6. 두 사전 분포를 한눈에
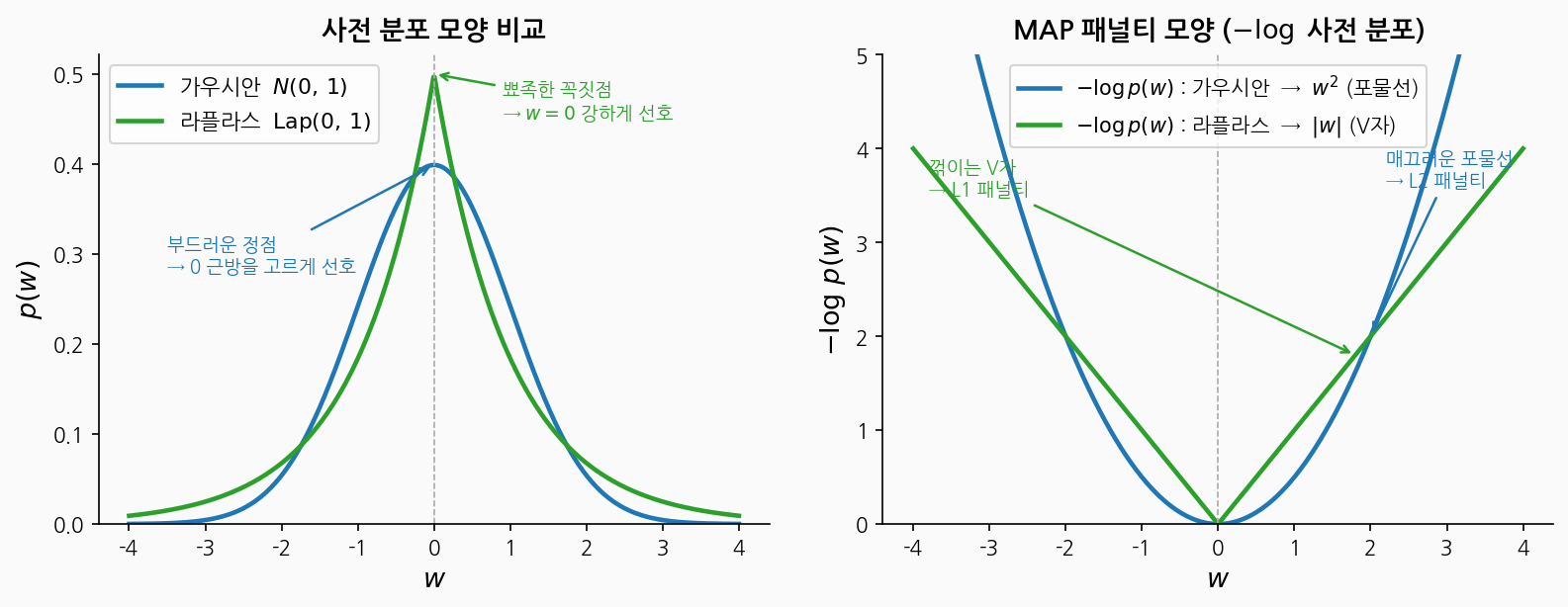 왼쪽: 분포 모양. 오른쪽: $-\log p(w)$ = MAP 패널티 모양.
왼쪽: 분포 모양. 오른쪽: $-\log p(w)$ = MAP 패널티 모양.
| 가우시안 사전 | 라플라스 사전 | |
|---|---|---|
| 분포 정점 | 부드러운 곡면 | 뾰족한 꼭짓점 |
| $-\log p(w)$ | 포물선 $\propto w^2$ | V자 $\propto \lvert w \rvert$ |
| MAP 패널티 | L2 (Ridge) | L1 (Lasso) |
| 계수 거동 | 0 근방으로 수축 | 일부가 정확히 0 |
7. $\lambda$의 베이지안 해석
Ridge의 경우: $\lambda = \sigma^2 / \tau^2$
| 상황 | 의미 | $\lambda$ |
|---|---|---|
| $\tau^2$이 크다 | 계수가 클 수도 있다는 약한 믿음 | 작아짐 → 규제 약해짐 |
| $\tau^2$이 작다 | 계수가 0에 가까울 것이라는 강한 믿음 | 커짐 → 규제 강해짐 |
| $\sigma^2$이 크다 | 데이터가 잡음이 많아 신뢰도 낮음 | 커짐 → 사전 믿음에 의존 |
| $\sigma^2$이 작다 | 데이터가 깨끗하고 신뢰도 높음 | 작아짐 → 데이터를 따름 |
$\lambda$는 “데이터를 얼마나 믿는가”와 “사전 믿음을 얼마나 믿는가”의 비율입니다.
8. 코드 — λ와 사전 분포의 관계 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import numpy as np
from sklearn.linear_model import Ridge, Lasso
from sklearn.datasets import make_regression
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
X, y = make_regression(n_samples=100, n_features=20, noise=10, random_state=42)
scaler = StandardScaler()
X = scaler.fit_transform(X)
sigma2 = 100 # 잡음 분산 (고정)
# τ²를 바꾸면 λ = σ²/τ²가 바뀐다
tau2_values = [0.1, 1.0, 10.0, 100.0]
print(f"{'τ²':>8} {'λ=σ²/τ²':>12} {'계수 L2 norm':>14}")
print("-" * 38)
for tau2 in tau2_values:
lam = sigma2 / tau2
coef = Ridge(alpha=lam).fit(X, y).coef_
print(f"{tau2:>8.1f} {lam:>12.1f} {np.linalg.norm(coef):>14.3f}")
1
2
3
4
5
6
τ² λ=σ²/τ² 계수 L2 norm
--------------------------------------
0.1 1000.0 0.619
1.0 100.0 2.854
10.0 10.0 9.821
100.0 1.0 24.337
τ²가 클수록(계수가 커도 된다는 약한 사전 믿음) λ가 작아지고 계수 norm이 커집니다. τ²가 작을수록(계수가 0 근방이어야 한다는 강한 믿음) λ가 커지고 계수가 강하게 수축합니다.
1
2
3
4
5
6
7
8
9
10
11
# λ에 따른 계수 수축 시각화
lambdas = np.logspace(-1, 4, 50)
norms = [np.linalg.norm(Ridge(alpha=l).fit(X, y).coef_) for l in lambdas]
plt.figure(figsize=(7, 4))
plt.semilogx(lambdas, norms)
plt.xlabel("λ (규제 강도)")
plt.ylabel("계수 L2 norm")
plt.title("λ가 커질수록 MAP 추정값이 0으로 수렴")
plt.tight_layout()
plt.show()
마치며
정리하면:
- 가우시안 잡음을 가정한 선형 회귀에서 MLE = OLS
- 여기에 가우시안 사전 분포를 추가해 MAP를 구하면 = Ridge
- 라플라스 사전 분포를 추가해 MAP를 구하면 = Lasso
규제는 단순한 과적합 방지 트릭이 아닙니다.
“계수가 어떻게 분포할 것이다”라는 사전 믿음을 모델에 명시적으로 주입하는 행위입니다.
가우시안 사전의 부드러운 정점 → L2 포물선 패널티 → 계수 수축
라플라스 사전의 뾰족한 꼭짓점 → L1 V자 패널티 → 계수 소거
분포의 모양이 곧 규제의 성질을 결정합니다.