시계열 분석 입문: Stationary vs Non-Stationary
서론
시계열 분석을 처음 공부하다 보면 “정상성(Stationarity)”이라는 단어를 피할 수 없습니다.
ARMA나 VAR 같은 고전적인 시계열 모델들의 이론적 기반을 들여다보면, 대체로 정상성(stationarity) 또는 안정성 조건 위에서 전개됩니다. ARIMA는 비정상 시계열을 차분해 정상적인 ARMA 구조로 바꾸는 접근이고, GARCH는 조건부 분산 과정의 안정성 조건을 따로 요구합니다.
이 포스팅에서는 아래 질문들을 순서대로 풀어갑니다.
- 정상성이란 무엇인가?
- 왜 비정상 시계열로는 분석/예측이 어려운가?
- 단위근(Unit Root)이란 무엇이며, 어떻게 검정하는가?
- 시계열을 구성하는 요소는 무엇인가?
- 어떤 요소가 비정상성을 유발하며, 어떻게 정상화하는가?
- 종합 예시: 단계별 정상화 파이프라인
1. 정상성(Stationarity)이란?
직관적으로 말하면, 시계열의 통계적 특성이 시간이 흘러도 변하지 않는 상태입니다.
“통계적 특성”은 크게 세 가지를 의미합니다.
| 특성 | 수식 | 의미 |
|---|---|---|
| 평균 | $E[y_t] = \mu$ | 시간에 무관하게 일정 |
| 분산 | $\text{Var}(y_t) = \sigma^2 < \infty$ | 시간에 무관하게 유한·일정 |
| 자기공분산 | $\text{Cov}(y_t, y_{t-k}) = \gamma(k)$ | 시차(lag) $k$에만 의존, $t$에는 무관 |
1.1 강정상성(Strict Stationarity)
임의의 시점 집합 ${t_1, \ldots, t_n}$에 대해, 결합 분포 자체가 시간 이동에 불변인 경우입니다.
\[(y_{t_1}, \ldots, y_{t_n}) \overset{d}{=} (y_{t_1+h}, \ldots, y_{t_n+h}), \quad \forall h\]모멘트(moment)란: 확률변수의 분포 모양을 수치로 요약하는 양입니다. $k$차 모멘트는 $E[X^k]$로 정의되며, 첫 번째와 두 번째 모멘트가 가장 친숙합니다.
- 1차 모멘트: $E[X] = \mu$ — 평균(중심 위치)
- 2차 중심모멘트: $E[(X-\mu)^2] = \sigma^2$ — 분산(퍼짐)
- 3차 중심모멘트: 왜도(skewness, 비대칭성)
- 4차 중심모멘트: 첨도(kurtosis, 꼬리의 두꺼움)
강정상성은 모멘트 몇 개가 아니라 결합분포 자체가 시간 이동에 대해 변하지 않는다는 조건입니다. 만약 모든 모멘트가 존재한다면 평균·분산뿐 아니라 왜도·첨도 같은 고차 모멘트도 시간에 따라 변하지 않습니다.
따라서 강정상성은 매우 강한 조건입니다. 이론적으로 깔끔하지만, 실제 데이터에서 이를 검증하는 것은 사실상 불가능합니다.
1.2 약정상성(Weak / Covariance Stationarity)
실무와 대부분의 교과서에서 “정상성”이라 함은 사실상 약정상성을 의미합니다.
- $E[y_t] = \mu$ (일정한 평균)
- $E[y_t^2] < \infty$ (유한 분산)
- $\text{Cov}(y_t, y_{t-k}) = \gamma(k)$ (자기공분산이 시차에만 의존)
분포 전체가 아닌 1·2차 모멘트만 불변이면 됩니다. 시계열이 가우시안 과정이라면 평균 함수와 공분산 함수가 유한차원 결합분포를 결정하므로 강/약정상성이 사실상 동치가 됩니다. 그래서 많은 모수적 시계열 모델은 약정상성으로 충분합니다.
실무 요약: ARIMA, SARIMA, VAR 등 고전 모델에서 요구하는 정상성은 약정상성입니다.
2. 왜 비정상 시계열은 분석/예측이 어려운가?
비정상 시계열을 그대로 고전 모델에 투입했을 때 발생하는 문제는 크게 두 가지입니다.
2.1 허구적 회귀(Spurious Regression)
서로 무관한 두 비정상 시계열 $y_t$와 $x_t$를 단순 회귀하면, 실제로는 아무 관계가 없어도 $R^2$가 높고 t-통계량이 유의하게 나타납니다. Granger & Newbold(1974)가 실험적으로 보였고, Phillips(1986)가 이론적으로 증명한 현상입니다.
추정량이 일치성(consistency)을 잃고, 검정통계량이 표준 분포를 따르지 않아서 p-value 자체가 무의미해집니다.
2.2 파라미터 추정의 불안정성
ARMA 모델은 정상성 조건 아래서만 MLE·OLS 추정량이 일치성과 점근적 정규성을 가집니다. 비정상 데이터에서는 추정된 파라미터의 표준오차가 발산하거나 왜곡되어, 신뢰구간과 예측 구간 자체를 신뢰할 수 없게 됩니다.
즉, “정상성이 전제되어야 추정된 파라미터가 통계적으로 의미 있고, 예측 구간도 신뢰할 수 있다”는 것이 핵심입니다.
잠깐 용어:
- MLE (Maximum Likelihood Estimation, 최대가능도추정): “관찰된 데이터를 가장 그럴듯하게 만드는 모수 값을 고른다”는 추정 원리. 가능도 함수 $L(\boldsymbol{\theta} \mid \text{data})$를 최대화하는 $\boldsymbol{\theta}$를 추정값으로 삼습니다(→ 가능도와 MLE의 발상).
- OLS (Ordinary Least Squares, 보통최소제곱법): “예측값과 실제값의 제곱오차 합을 최소화하는 모수 값을 고른다”는 추정 원리. 선형회귀의 표준 추정 방법으로, 오차가 정규분포일 때 OLS와 MLE는 같은 결과를 줍니다.
두 방법의 정확한 정의와 통계적 성질은 Casella & Berger(2002) Statistical Inference 7장에 정리되어 있습니다.
3. 단위근(Unit Root)
비정상성의 대표적 원인 중 하나가 단위근입니다.
AR(1) 모델 $y_t = \phi y_{t-1} + \epsilon_t$를 생각해 봅시다.
3.1 AR(1)이 어떻게 움직이는가
AR(1)은 현재 값이 직전 값에 $\phi$배만큼 의존하고, 거기에 새 충격 $\epsilon_t$가 더해진다는 가장 단순한 자기회귀 구조입니다. $\phi$ 값에 따라 시계열의 성격이 완전히 달라집니다.
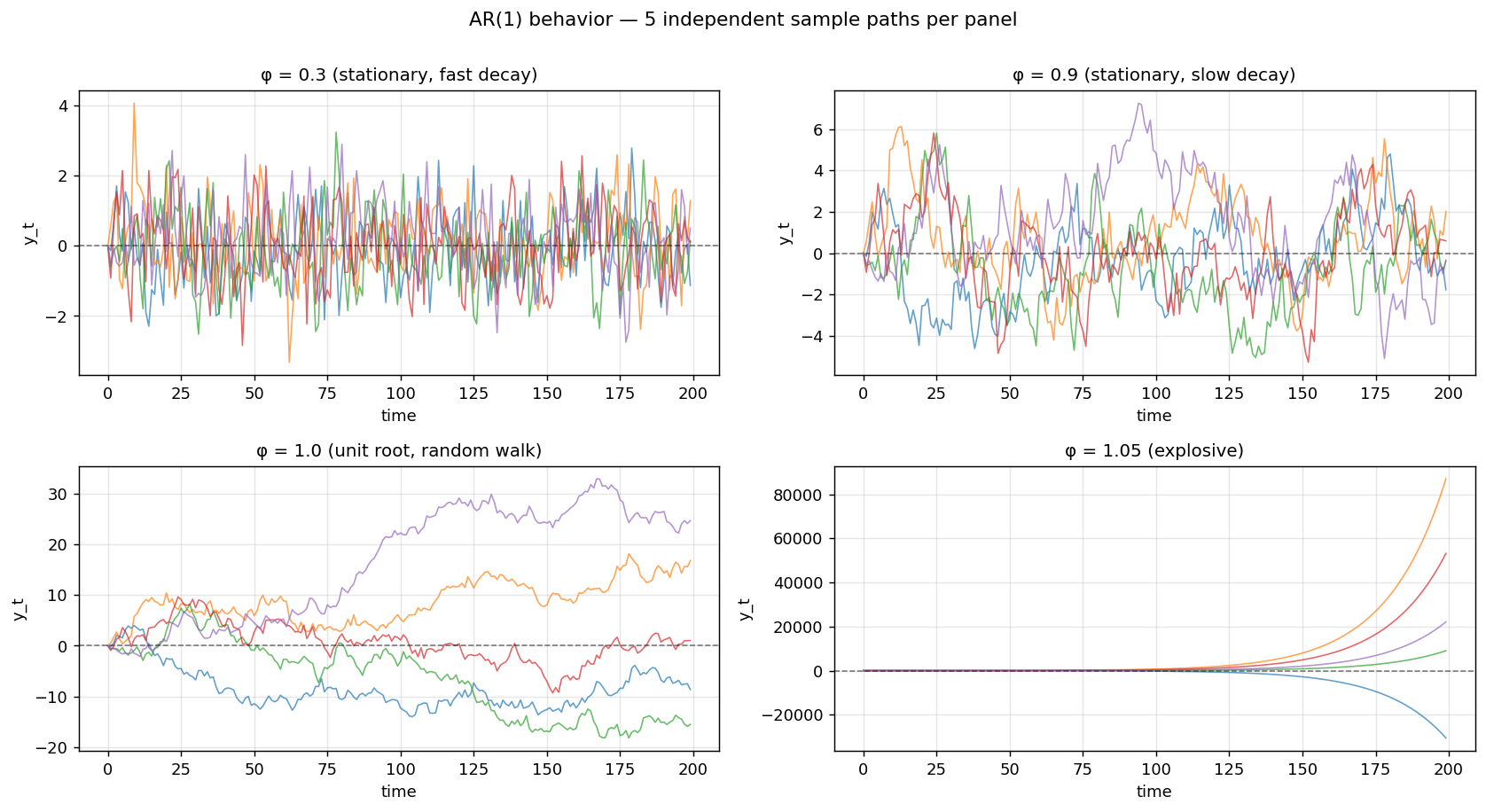
각 패널마다 같은 $\phi$ 값으로 5개의 독립적인 경로를 그렸습니다. 같은 모델이라도 노이즈가 매번 다르므로 결과는 매번 다릅니다.
- $\phi = 0.3$: 직전 값의 영향이 약해 빠르게 0 부근으로 회귀합니다. 다섯 경로 모두 0 근처에서 잘게 진동합니다.
- $\phi = 0.9$: 영향이 천천히 사라져 한쪽으로 길게 머무는 구간이 자주 보입니다. 그래도 결국에는 0 쪽으로 끌려옵니다.
- $\phi = 1.0$: 충격이 사라지지 않고 누적됩니다. 랜덤워크입니다. 다섯 경로가 다섯 방향으로 흩어집니다 — 0으로 끌려오는 메커니즘이 사라졌기 때문입니다.
- $\phi = 1.05$: 직전 값보다 더 크게 반영되어 시계열이 폭발적으로 발산합니다. 양/음 어느 쪽으로든 갑니다.
잠깐 짚고 가기 — $\phi > 0$인데 왜 시계열이 음(-)으로도 흘러갈까?
$\phi$의 부호는 시계열 값의 부호와 무관합니다. $\phi$는 직전 값과 같은 방향으로 갈지($\phi>0$), 반대 방향으로 갈지($\phi<0$) 만 정합니다. 시계열 자체의 부호는 누적된 노이즈 $\epsilon_t$가 결정합니다.
$\phi=1$인 랜덤워크의 경우 $y_t = \sum_i \epsilon_i$인데, 충격 $\epsilon_i$는 평균 0의 정규분포에서 뽑히므로 절반은 음수입니다. 초반 충격이 음수 우세였다면 시계열이 음의 영역으로 한참 흘러갑니다. 양수 $\phi$가 곱해지긴 하지만 누적되는 대상 자체가 음수일 수 있는 것이지요.
정상 AR(1)($\lvert \phi \rvert < 1$)의 이론적 평균은 0이지만 이는 무한히 긴 시계열의 기댓값이고, 유한한 샘플에서는 0을 한참 벗어난 구간이 흔히 나타납니다. 특히 $\phi$가 1에 가까울수록 0으로 회귀하는 속도가 느려서 한쪽 영역에 오래 머뭅니다.
핵심은 $\phi$가 1을 경계로 정상/비정상이 갈린다는 점입니다.
- $\lvert \phi \rvert < 1$: 정상 과정 (충격이 기하급수적으로 소멸)
- $\phi = 1$: 단위근 → 랜덤워크, 충격이 영구적으로 누적
- $\lvert \phi \rvert > 1$: 폭발적 과정 (발산)
$\phi = 1$인 경우를 특성방정식 $1 - \phi L = 0$의 근이 단위원(unit circle) 위에 있다고 해서 단위근이라 부릅니다. 이 경우 분산이 $t$에 비례하여 증가하므로 약정상성 조건을 위반합니다.
\[\text{Var}(y_t) = t\sigma^2 \to \infty \quad (t \to \infty)\]3.2 왜 분산이 $t$에 비례하는가
$\phi = 1$이면 AR(1)은 다음과 같이 단순해집니다.
\[y_t = y_{t-1} + \epsilon_t\]이걸 재귀적으로 풀면 (편의상 $y_0 = 0$):
\[y_t = \epsilon_1 + \epsilon_2 + \cdots + \epsilon_t = \sum_{i=1}^{t} \epsilon_i\]즉 현재 값은 지금까지의 모든 충격의 합입니다. 충격 $\epsilon_i$가 서로 독립이고 분산이 $\sigma^2$이라고 하면, 독립확률변수의 합의 분산은 분산의 합이므로:
\[\text{Var}(y_t) = \text{Var}\!\left(\sum_{i=1}^{t} \epsilon_i\right) = \sum_{i=1}^{t} \text{Var}(\epsilon_i) = t\sigma^2\]$t$가 커질수록 분산이 선형으로 늘어납니다. 약정상성 조건 (ii) “분산이 $t$와 무관하게 유한 상수”를 정면으로 위반합니다.
$\lvert \phi \rvert < 1$일 때는 옛날 충격에 $\phi^{t-i}$ 가중치가 붙어서 멀수록 기하급수적으로 줄어들기 때문에 분산이 $\sigma^2/(1-\phi^2)$라는 유한 값으로 수렴합니다. $\phi$가 1에 도달하는 순간 이 수렴 메커니즘이 깨지면서 분산이 발산하는 것입니다.
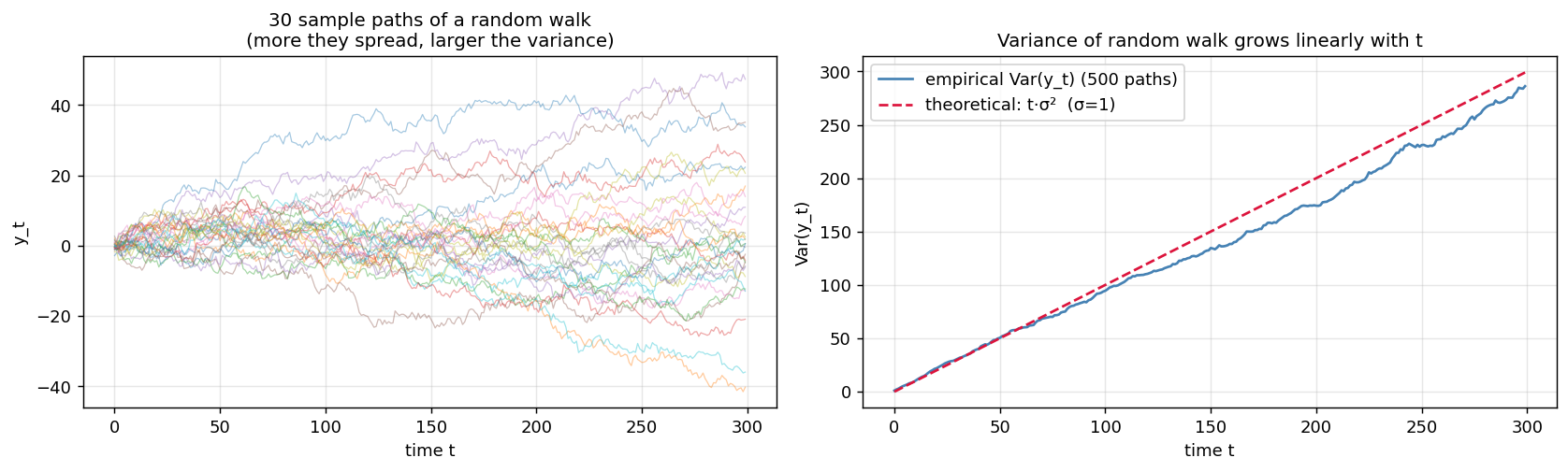
위 그림은 같은 분포에서 뽑은 500개의 랜덤워크 경로의 시점별 분산을 측정한 결과입니다. 경험적 분산이 이론값 $t\sigma^2$ (빨간 점선)을 거의 정확히 따라갑니다.
3.3 ADF 검정 (Augmented Dickey-Fuller Test)
단위근 존재 여부를 검정하는 가장 보편적인 방법입니다. 단, 검정식에 상수만 넣을지(regression='c'), 상수와 선형 추세를 함께 넣을지(regression='ct')에 따라 결론이 달라질 수 있습니다. 눈으로 봤을 때 선형 추세가 강하면 추세 옵션도 함께 확인해야 합니다.
- $H_0$: 단위근이 존재한다 (비정상)
- $H_1$: 단위근이 없다 (정상)
1
2
3
4
5
6
7
8
9
10
11
12
from statsmodels.tsa.stattools import adfuller
import pandas as pd
def run_adf(series: pd.Series, label: str = "Series") -> None:
result = adfuller(series.dropna(), autolag="AIC")
print(f"[{label}]")
print(f" ADF Statistic : {result[0]:.4f}")
print(f" p-value : {result[1]:.4f}")
for key, val in result[4].items():
print(f" Critical ({key}): {val:.4f}")
conclusion = "비정상 (단위근 존재)" if result[1] > 0.05 else "정상"
print(f" 판정 : {conclusion}\n")
주의: ADF 검정은 귀무가설이 “비정상”이므로, p-value > 0.05이면 비정상을 기각하지 못합니다. 단위근 검정은 검정력(power)이 낮고 구조적 변화에 취약하므로, KPSS 검정(귀무가설: 정상)과 함께 사용하면 더 견고한 판단이 가능합니다.
검정 결론을 어떻게 읽어야 하는가
시계열 정상성 검정은 귀무가설을 어떻게 잡느냐에 따라 결론을 읽는 방향이 달라집니다. 둘을 헷갈리면 정반대 결론을 내릴 수 있으므로 한 번 정리하고 갑니다.
검정 귀무가설 $H_0$ 대립가설 $H_1$ p ≤ 0.05일 때 p > 0.05일 때 ADF 단위근이 있다 (비정상) 단위근이 없다 $H_0$ 기각 → 정상성 가능 $H_0$ 기각 못함 → 비정상으로 다룸 KPSS 정상이다 비정상이다 $H_0$ 기각 → 비정상 $H_0$ 기각 못함 → 정상성 가능 두 가지를 짚어 둡니다.
(1) “기각하지 못함”은 “참이라고 인정함”이 아닙니다. 통계검정은 비대칭이라, 증거가 부족할 뿐 귀무가설이 맞다는 것을 증명하지는 않습니다. 그래서 위 표에서도 “정상이다”가 아니라 “정상성 가능”이라고 쓴 것입니다.
(2) ADF는 “비정상”이 아닌 “단위근”을 검정합니다. 단위근이 없어도 비정상일 수 있습니다(분산 변화, 추세 정상성, 구조적 변화 등). 그래서 ADF 단독으로 정상성을 단정 짓지 않고 KPSS와 함께 봅니다. 두 검정이 모두 정상성을 지지할 때 (“ADF p ≤ 0.05 AND KPSS p > 0.05”) 결론이 가장 견고합니다. KPSS 역시
regression='c'는 수준 정상성,regression='ct'는 추세 정상성을 검정하므로 데이터의 추세 구조를 먼저 눈으로 확인하는 것이 좋습니다.
4. 시계열의 구성 요소
시계열 $y_t$는 일반적으로 아래 네 가지 요소로 분해됩니다.
\[y_t = T_t + S_t + C_t + R_t\]| 기호 | 이름 | 설명 |
|---|---|---|
| $T_t$ | 추세(Trend) | 장기적으로 증가/감소하는 방향성 |
| $S_t$ | 계절성(Seasonality) | 일정 주기로 반복되는 패턴 (주, 월, 연) |
| $C_t$ | 순환(Cycle) | 경기 사이클 같은 장기 비주기 변동 |
| $R_t$ | 잔차(Residual/Irregular) | 위 셋으로 설명되지 않는 불규칙 성분 |
실무에서는 순환 성분을 추세에 흡수시켜 $T_t + C_t$로 묶는 경우가 많습니다.
분해 방식은 두 가지입니다.
- 가법 모형: $y_t = T_t + S_t + R_t$ (계절 변동 폭이 일정할 때)
- 승법 모형: $y_t = T_t \times S_t \times R_t$ (변동 폭이 수준에 비례할 때 → 로그 변환으로 가법화 가능)
실제로 statsmodels의 seasonal_decompose를 쓰면 한 줄로 분해할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose
# 추세 + 계절성 + 노이즈를 가진 합성 시계열
np.random.seed(7)
n = 144
t = np.arange(n)
y = 100 + 2.5 * t + 30 * np.sin(2 * np.pi * t / 12) + np.random.normal(0, 8, n)
idx = pd.date_range('2014-01', periods=n, freq='MS')
series = pd.Series(y, index=idx)
result = seasonal_decompose(series, model='additive', period=12)
result.plot()
plt.tight_layout()
plt.show()
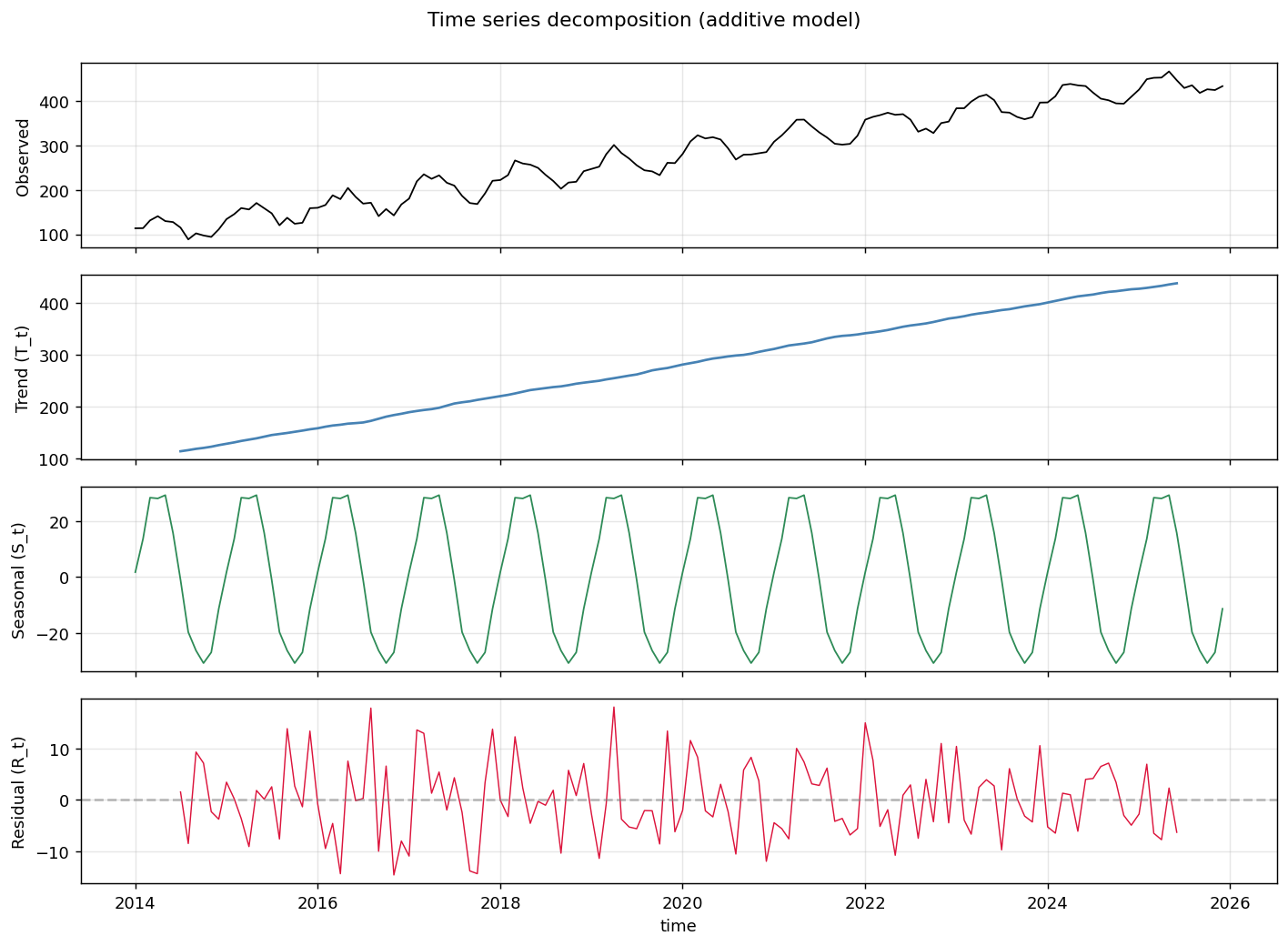
위에서부터 차례로 원본(Observed) → 추세(Trend, $T_t$) → 계절성(Seasonal, $S_t$) → 잔차(Residual, $R_t$) 입니다. 추세는 부드러운 우상향 곡선, 계절성은 매년 동일한 진폭으로 반복되는 사인파, 잔차는 평균 0 부근에서 무작위로 흔들리는 모습이 깔끔하게 분리됩니다.
참고:
seasonal_decompose는 이동평균 기반의 고전적 분해라서 추세 끝부분에 결측이 생기고 충격에 약합니다. 보다 정교한 분해가 필요하면 STL(Seasonal-Trend decomposition using LOESS) 을 권합니다 (from statsmodels.tsa.seasonal import STL).
5. 어떤 성분이 비정상성을 유발하며, 어떻게 정상화하는가?
5.1 추세(Trend) → 차분 또는 추세 제거
추세는 평균이 시간에 따라 변화하게 만들어 정상성을 위반합니다.
결정론적 추세(Deterministic Trend): 회귀로 추세를 제거(Trend-Stationary, TS 과정)
1
2
3
4
5
6
7
8
import numpy as np
from statsmodels.regression.linear_model import OLS
import statsmodels.api as sm
t = np.arange(len(series))
X = sm.add_constant(t)
model = OLS(series, X).fit()
detrended = series - model.fittedvalues
확률적 추세(Stochastic Trend, 단위근): 차분(Differencing)으로 제거 (Difference-Stationary, DS 과정)
\[\Delta y_t = y_t - y_{t-1}\]1
diff_series = series.diff().dropna()
DS vs TS 구분이 중요한 이유: TS 과정에 차분을 적용하면 과차분(overdifferencing)이 발생하고, DS 과정에 추세 제거만 하면 여전히 비정상입니다. ADF/KPSS 검정으로 판단하는 것이 원칙입니다.
5.2 계절성(Seasonality) → 계절 차분 또는 계절 조정
계절성은 주기적으로 평균이 이동하므로 정상성을 위반합니다.
계절 주기 $m$에 대한 계절 차분:
\[\Delta_m y_t = y_t - y_{t-m}\]1
2
m = 12 # 월별 데이터
seasonal_diff = series.diff(m).dropna()
5.3 분산의 비균일성(Heteroscedasticity) → 변환
분산이 시간에 따라 변하면 약정상성의 분산 조건을 위반합니다. 이분산성의 형태에 따라 적합한 변환을 선택합니다.
로그 변환 (Log Transformation)
\[y_t' = \log(y_t)\]분산이 수준(level)에 비례하여 증가하는 승법 구조에 효과적입니다. 로그를 취하면 승법 구조가 가법 구조로 전환되어 분산이 안정됩니다.
\[\text{Var}(y_t) \propto \mu_t^2 \;\Rightarrow\; \text{Var}(\log y_t) \approx \text{const}\]- 양수 데이터에만 적용 가능 ($y_t > 0$)
- 로그 변환 후 1차 차분하면 로그수익률 $r_t = \log(y_t / y_{t-1})$ — 상대 변화율로 해석
1
2
3
import numpy as np
log_series = np.log(series)
Box-Cox 변환
로그 변환의 일반화입니다. 매개변수 $\lambda$를 데이터에서 추정해 최적 분산 안정화 변환을 찾습니다.
\[y_t^{(\lambda)} = \begin{cases} \dfrac{y_t^\lambda - 1}{\lambda} & \lambda \neq 0 \\[6pt] \log(y_t) & \lambda = 0 \end{cases}\]$\lambda$ 값에 따라 변환의 형태가 달라집니다.
| $\lambda$ | 변환 형태 | 전형적 적용 상황 |
|---|---|---|
| $-2$ | $1/y_t^2$ | 분산이 수준의 제곱에 비례 |
| $-1$ | $1/y_t$ (역수 변환) | 분산이 수준에 강하게 비례 |
| $-0.5$ | $1/\sqrt{y_t}$ | |
| $\mathbf{0}$ | $\log(y_t)$ (로그 변환) | 분산이 수준에 비례 — 가장 흔함 |
| $0.5$ | $\sqrt{y_t}$ (제곱근 변환) | 카운트 데이터, 포아송 분포 |
| $1$ | $y_t$ (변환 없음) | 이미 등분산 |
| $2$ | $y_t^2$ (제곱 변환) | 분산이 수준에 반비례 |
1
2
3
4
5
from scipy.stats import boxcox
transformed, lam = boxcox(series[series > 0])
print(f"최적 λ: {lam:.4f}")
# λ ≈ 0 이면 로그 변환과 동일
로그 vs Box-Cox: $\lambda$를 데이터로 추정하는 Box-Cox가 더 유연하지만 $\lambda \approx 0$이 자주 나옵니다. 로그 변환은 해석이 직관적(상대 변화)이라는 장점이 있어, 실무에서는 로그를 먼저 시도하는 것이 일반적입니다.
수익률 변환 + GARCH — 변동성 군집화를 모델링하는 접근
금융 시계열처럼 변동성 군집화(volatility clustering)가 있는 경우, 로그·Box-Cox 변환만으로는 이분산성이 제거되지 않습니다.
로그수익률로 변환하면:
\[r_t = \log\!\left(\frac{y_t}{y_{t-1}}\right) = \Delta \log y_t\]수준의 추세와 이분산 일부를 완화할 수 있지만, 수익률 잔차의 분산이 시간에 따라 변하는 조건부 이분산 구조는 여전히 남습니다. 큰 충격 다음에 큰 변동이, 잠잠한 구간 다음에 잠잠한 구간이 이어지는 패턴이 지속됩니다.
이 잔류 이분산은 단순 변환으로 “제거”할 수 있는 것이 아니라, 분산 과정 자체를 모델링해야 합니다. 이때 사용하는 모형이 GARCH입니다.
→ 변동성 군집화를 직접 포착하는 방법은 ARCH·GARCH 포스트를 참고하세요.
5.4 정리: 비정상 원인과 처방
| 비정상 원인 | 정상화 방법 |
|---|---|
| 결정론적 추세 | 추세 회귀 후 잔차 사용 (Detrending) |
| 확률적 추세 (단위근) | 1차 차분 $\Delta y_t$ |
| 계절성 | 계절 차분 $\Delta_m y_t$ |
| 이분산성 (수준 비례) | 로그·Box-Cox 변환 |
| 이분산성 (변동성 군집화) | 수익률 변환 후 GARCH 모형 적합 |
| 추세 + 계절성 복합 | 변환 후 차분, 계절 차분 복합 적용 |
6. 종합 예시: 단계별 정상화 파이프라인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.stattools import adfuller, kpss
from statsmodels.tsa.seasonal import seasonal_decompose
def check_stationarity(series: pd.Series, label: str = "") -> None:
"""ADF + KPSS 이중 검정"""
adf = adfuller(series.dropna(), autolag="AIC")
kpss_stat, kpss_p, _, _ = kpss(series.dropna(), regression="c", nlags="auto")
print(f"=== {label} ===")
print(f"ADF p-value : {adf[1]:.4f} → {'정상' if adf[1] < 0.05 else '비정상'}")
print(f"KPSS p-value : {kpss_p:.4f} → {'정상' if kpss_p > 0.05 else '비정상'}")
print()
# 예시 데이터 (AirPassengers 스타일)
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv"
df = pd.read_csv(url, index_col=0, parse_dates=True)
series = df.squeeze()
# Step 1: 원본 검정
check_stationarity(series, "원본")
# Step 2: 로그 변환 (이분산 완화)
import numpy as np
log_series = np.log(series)
check_stationarity(log_series, "로그 변환")
# Step 3: 계절 차분 (m=12)
seasonal_diff = log_series.diff(12).dropna()
check_stationarity(seasonal_diff, "로그 + 계절차분")
# Step 4: 1차 차분 추가
final = seasonal_diff.diff().dropna()
check_stationarity(final, "로그 + 계절차분 + 1차차분")
마치며
정상성은 단순히 “이 데이터가 좋은 데이터냐”의 문제가 아닙니다.
많은 고전 시계열 모델이 통계적으로 의미 있는 결과를 내려면 반드시 확인해야 하는 입력 조건이며, 이를 어기면 파라미터 추정과 예측 구간 전체가 신뢰를 잃을 수 있습니다.
비정상성의 원인을 진단하고 — 추세인지, 계절성인지, 이분산인지, 단위근인지 — 그에 맞는 처방을 내리는 것이 시계열 분석의 첫 번째 단계입니다.
다음 편에서는 정상화된 시계열에 ARMA 모형을 적합하는 과정, 즉 모수 추정과 모형 선택(AIC/BIC 기반 차수 결정)을 다루겠습니다.
참고문헌
- Box, G. E. P., Jenkins, G. M., Reinsel, G. C., & Ljung, G. M. (2015). Time Series Analysis: Forecasting and Control (5th ed.). Wiley.
- Hamilton, J. D. (1994). Time Series Analysis. Princeton University Press.
- Granger, C. W. J., & Newbold, P. (1974). Spurious regressions in econometrics. Journal of Econometrics, 2(2), 111–120.
- Phillips, P. C. B. (1986). Understanding spurious regressions in econometrics. Journal of Econometrics, 33(3), 311–340.
- Dickey, D. A., & Fuller, W. A. (1979). Distribution of the estimators for autoregressive time series with a unit root. Journal of the American Statistical Association, 74(366), 427–431.
- Kwiatkowski, D., Phillips, P. C. B., Schmidt, P., & Shin, Y. (1992). Testing the null hypothesis of stationarity against the alternative of a unit root. Journal of Econometrics, 54(1–3), 159–178.
AI의 도움을 받아 작성되었으며 최대한 레퍼런스를 밝히려 노력했으나 오류가 있을 수 있으니 정확한 정보를 다시 한번 확인하시기 바랍니다.