AR, MA, ARMA, ARIMA, SARIMA — 고전 시계열 모형 한 바퀴
지난 포스팅에서 정상성과 모수 추정의 발상을 정리했습니다. 이번 글에서는 그 위에 본격적인 모형들을 올려 보겠습니다. AR, MA, ARMA, ARIMA, SARIMA, 그리고 SARIMAX까지. 이름이 많아 보이지만 실은 AR과 MA라는 두 가지 부품을 어떻게 조립하느냐의 차이입니다.
이번 글의 흐름은 이렇습니다.
- AR(1)과 MA(1) — 각각 한 시점 충격에 어떻게 반응하는가
- 차수 p, q를 어떻게 결정하는가 — ACF/PACF의 역할
- ARMA, ARIMA — 두 부품을 합치고, 차분으로 비정상을 다스리기
- SARIMA — 계절성까지 다루기
- SARIMAX — 외생변수를 추가하기 (그리고 다변량 시계열은 다른 이야기)
1. AR(1)과 MA(1) — 두 가지 부품
1.1 AR(1) — 자기회귀(AutoRegressive)
가장 단순한 자기회귀 모형 AR(1)은 다음과 같이 정의됩니다.
\[y_t = \phi \, y_{t-1} + \epsilon_t\]여기서 $\epsilon_t$는 평균 0, 분산 $\sigma^2$의 백색잡음(white noise)입니다.1 현재 값이 직전 값에 $\phi$배만큼 의존하고, 거기에 새 충격 $\epsilon_t$가 더해진다는 구조입니다.
핵심 모수는 $\phi$ 하나입니다. $\phi$의 값이 시계열의 성격을 결정합니다.
- $\lvert \phi \rvert < 1$: 정상 과정
- $\phi = 1$: 단위근 (랜덤워크)
- $\lvert \phi \rvert > 1$: 폭발적 과정
이전 글에서 $\phi$ 값에 따라 시계열이 어떻게 달라지는지를 다루었으니, 여기서는 한 발 더 들어가서 충격이 어떻게 전파되는가를 보겠습니다.
1.2 MA(1) — 이동평균(Moving Average)
이름은 이동평균이지만, 일반적으로 말하는 “이동평균선”과는 다릅니다. 과거 충격들의 가중합을 의미합니다.
\[y_t = \epsilon_t + \theta \, \epsilon_{t-1}\]핵심 모수는 $\theta$ 하나입니다. 현재 값이 현재 충격 $\epsilon_t$와 직전 충격 $\epsilon_{t-1}$의 합으로 정의되는 구조입니다.
여기서 헷갈리지 않게 짚고 가야 할 것이 있습니다. AR(1)에서는 “직전 값 $y_{t-1}$”이 직접 들어가고, MA(1)에서는 “직전 충격 $\epsilon_{t-1}$”이 들어갑니다. 이 차이가 두 모형의 행동 방식을 결정합니다.
잠깐 짚고 가기 — MA(1)에서 $\theta = 1$이면 단위근일까?
아래 설명은 이 글의 부호 convention인 $y_t = \epsilon_t + \theta \epsilon_{t-1}$ 기준입니다. 교재에 따라 MA 다항식의 부호를 반대로 쓰기도 하므로 해석할 때 convention을 확인해야 합니다.AR(1)에서 $\phi = 1$을 단위근이라 부르고 비정상의 원인이라 했지요. 그러면 MA(1)에서 $\theta = 1$이어도 단위근일까요? 답은 “단위근이지만 의미가 정반대” 입니다.
MA(1)의 분산을 직접 계산해 보면 $\text{Var}(y_t) = \sigma^2(1 + \theta^2)$로 모든 $\theta$에 대해 유한합니다. 즉 MA(1)은 $\theta$ 값과 무관하게 항상 약정상입니다. 단위근이 있어도 비정상이 되지 않아요.
그럼 $\theta = 1$일 때 무엇이 깨지는가? 가역성(invertibility) 입니다. $\lvert \theta \rvert < 1$인 가역적 MA(1)은 무한차수 AR로 다시 쓸 수 있습니다 — 즉 관측된 시계열로부터 과거 충격(잔차)들을 거꾸로 복원할 수 있어요. 이게 예측에서 결정적인 성질입니다. $\theta = 1$이면 이 복원이 불가능해지고, 오차분산을 함께 조정하면 $\theta$와 $1/\theta$인 두 모형이 같은 자기공분산 구조를 만들 수 있어 통계적으로 구분되지 않는 식별 문제도 생깁니다.2
정리하면 AR과 MA의 단위근은 거울 같은 대칭 구조를 가집니다.
AR(p) MA(q) 단위근일 때 깨지는 것 정상성 가역성 단위근일 때 시계열은 비정상 여전히 정상 의미 있는 표현 MA(∞) 표현 가능 AR(∞) 표현 가능 실무에서는 statsmodels의
SARIMAX가enforce_invertibility=True옵션으로 추정 과정에서 자동으로 가역 영역을 강제하니, 보통은 이 문제를 직접 만날 일이 없습니다. 다만 비정상 시계열을 과차분(overdifferencing) 했을 때 결과 시계열의 MA 부분에 $\theta = 1$이 등장하는 형태로 신호가 나타날 수 있습니다.
1.3 한 시점만 충격을 가하면 어떻게 될까
이게 두 모형의 차이를 가장 극명하게 보여 주는 실험입니다. 모든 시점에서 $\epsilon_t = 0$이고, 오직 $t=10$에서만 $\epsilon_{10} = 5$인 상황을 생각해 봅시다. 그 후의 시계열을 따라가 보면:
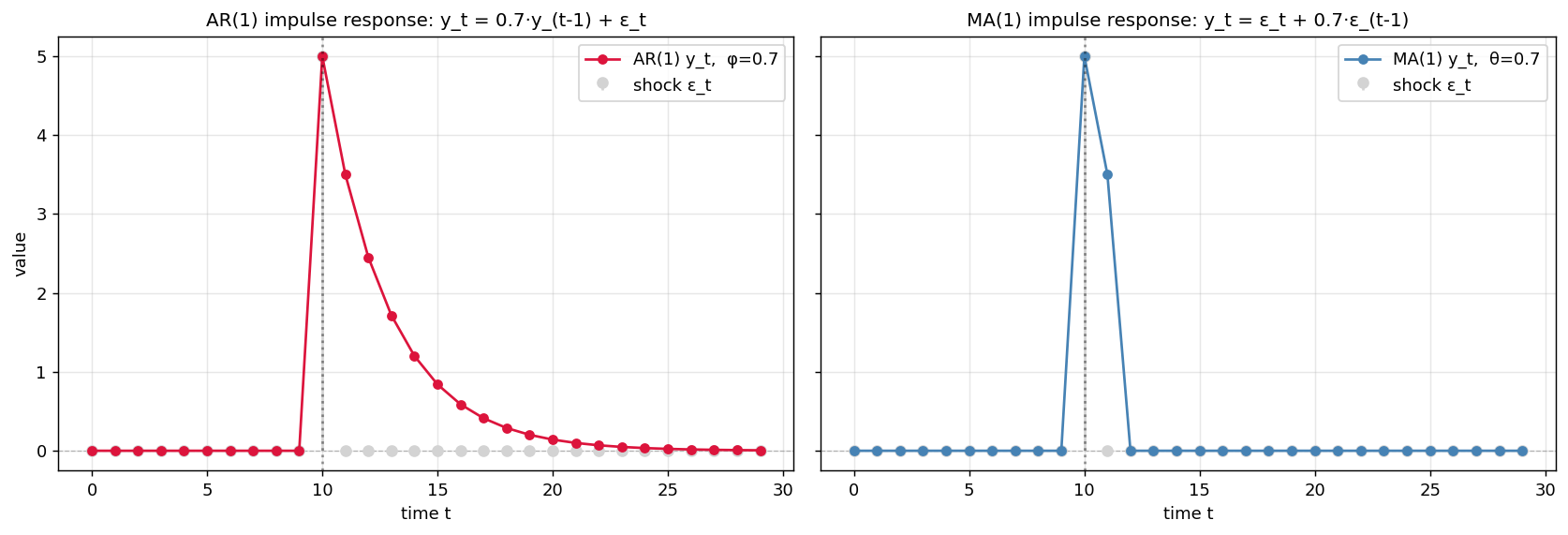
AR(1) (왼쪽, $\phi = 0.7$): $t=10$에서 5라는 충격을 맞고, 그 이후로는 충격이 0이지만 시계열은 $\phi = 0.7$의 비율로 곱해지며 천천히 0으로 수렴합니다. 직접 식을 풀어 보면:
\[\begin{aligned} y_{10} &= \phi \cdot 0 + 5 = 5 \\ y_{11} &= \phi \cdot 5 + 0 = 3.5 \\ y_{12} &= \phi \cdot 3.5 + 0 = 2.45 \\ y_{13} &= \phi \cdot 2.45 + 0 \approx 1.72 \\ &\vdots \end{aligned}\]일반화하면 충격 후 $k$시점이 지나면 $y_{10+k} = \phi^k \cdot 5$입니다. 충격이 무한히 길게, 기하급수적으로 감쇠하며 살아남는다는 것이 AR의 성격입니다.
MA(1) (오른쪽, $\theta = 0.7$): 같은 충격을 받으면 정확히 두 시점에만 영향이 나타나고 끝납니다.
\[\begin{aligned} y_{10} &= \epsilon_{10} + \theta \cdot \epsilon_{9} = 5 + 0 = 5 \\ y_{11} &= \epsilon_{11} + \theta \cdot \epsilon_{10} = 0 + 0.7 \cdot 5 = 3.5 \\ y_{12} &= \epsilon_{12} + \theta \cdot \epsilon_{11} = 0 + 0 = 0 \\ y_{13} &= 0 \end{aligned}\]MA(1)은 충격이 딱 한 스텝만 살아남고 끝납니다. MA(q)로 일반화하면 정확히 $q$ 스텝까지만 영향이 갑니다.
이 차이가 본질입니다.
한 줄 요약: AR은 충격이 끝없이 감쇠하며 흐른다. MA는 정해진 차수만큼만 영향을 끼치고 끝난다.
2. 차수 결정 — ACF와 PACF
AR과 MA를 일반화하면 AR(p), MA(q)가 됩니다. p와 q를 어떻게 결정할까요? 이게 모형 선택의 출발점입니다.
두 도구를 사용합니다.
- ACF (AutoCorrelation Function, 자기상관함수): 시점 $t$의 값과 시점 $t-k$의 값 사이의 상관계수. $k$는 시차(lag).
- PACF (Partial AutoCorrelation Function, 편자기상관함수): 중간 시차들의 영향을 통제한 뒤의 순수한 시차 $k$ 상관.3
각 시차마다 상관계수를 계산해서 막대그래프로 그리는 게 보통입니다. statsmodels로 한 줄이면 됩니다.
1
2
3
4
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plot_acf(series, lags=30)
plot_pacf(series, lags=30)
2.1 차수 결정 규칙
이론적으로는 다음과 같은 패턴이 나옵니다.4
| 모형 | ACF | PACF |
|---|---|---|
| AR(p) | 점진적으로 감쇠 (지수/사인) | 시차 $p$에서 절단 |
| MA(q) | 시차 $q$에서 절단 | 점진적으로 감쇠 |
| ARMA(p,q) | 점진적으로 감쇠 | 점진적으로 감쇠 |
“절단(cut-off)”이란 그 시차를 넘으면 막대 길이가 신뢰구간 안으로 떨어지는 것을 말합니다.
이 규칙이 작동하는 직관은 1.3절의 충격 반응에서 이미 보셨습니다.
- MA(q)는 충격이 정확히 q 시점까지만 영향이 가니까, $y_t$와 $y_{t-k}$의 상관(ACF)이 $k > q$에서 0이 됩니다 → ACF cut-off at q.
- AR(p)는 충격이 무한히 감쇠하니까 ACF는 절대 0이 안 되고 점진적으로 줄어듭니다. 대신 PACF는 시차 $p$에서 끊깁니다.
말로만 듣는 것보다 그림이 명확합니다. AR(1) ($\phi=0.7$)과 MA(1) ($\theta=0.7$) 시계열을 각각 길이 500으로 시뮬레이션한 뒤 ACF/PACF를 그려 봤습니다.
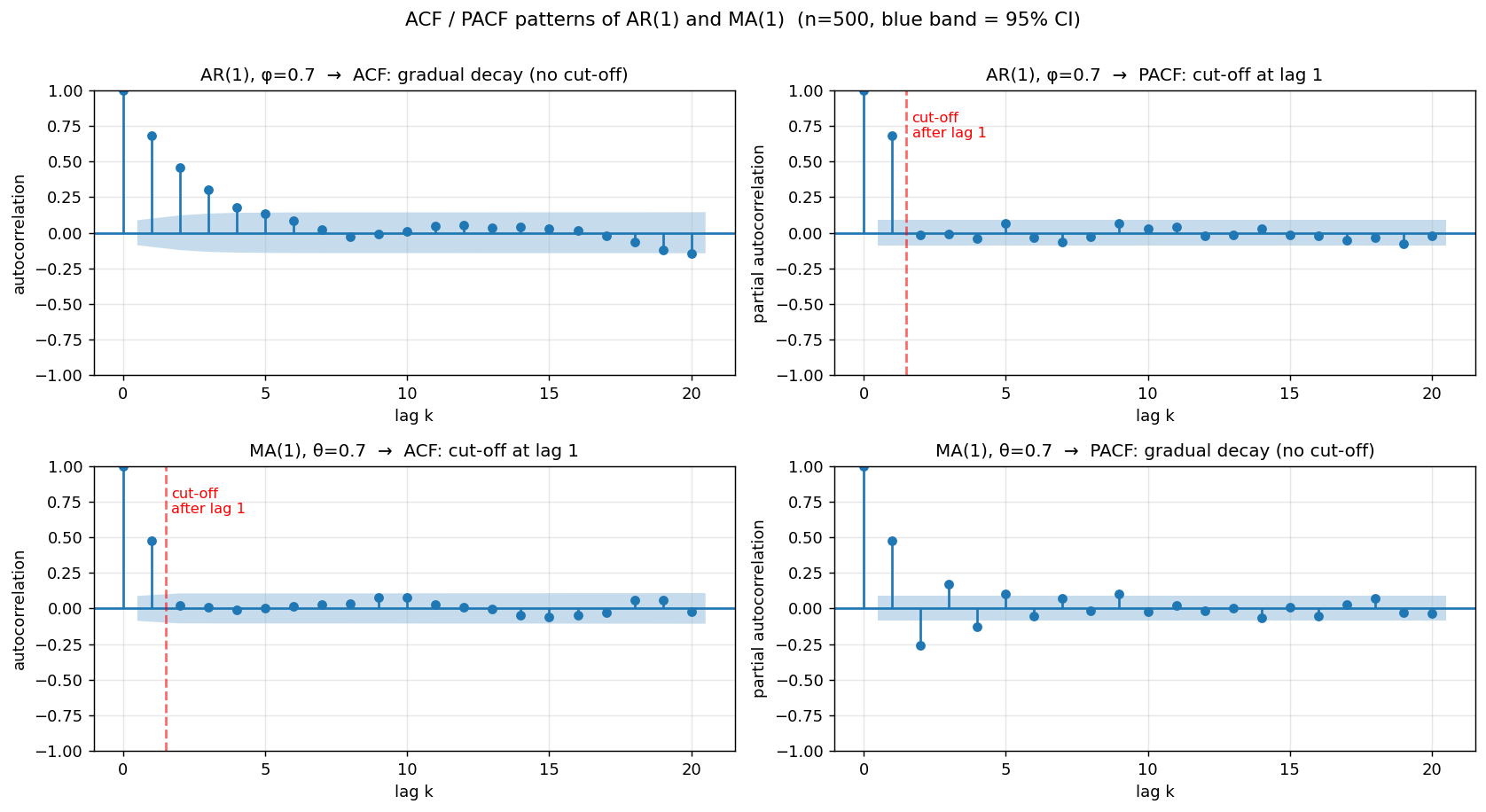
각 패널에서 옅은 파란 띠가 95% 신뢰구간입니다. 막대가 이 띠 안쪽에 들어오면 통계적으로 0과 구분되지 않는다, 즉 cut-off된 것으로 본다는 의미입니다.5
- AR(1) ACF (좌상): 시차 1, 2, 3, … 에서 값이 점진적으로 줄어들지만 한참 동안 신뢰띠 밖에 머뭅니다. 이게 “감쇠 (no cut-off)”의 모습입니다.
- AR(1) PACF (우상): 시차 1에서 큰 값(약 $\phi = 0.7$), 그 직후부터 모든 막대가 신뢰띠 안으로 들어갑니다 → lag 1에서 cut-off. AR의 차수 $p=1$을 정확히 짚어 줍니다.
- MA(1) ACF (좌하): 시차 1에서 큰 값, 그 이후 즉시 신뢰띠 안으로 들어갑니다 → lag 1에서 cut-off. MA의 차수 $q=1$을 정확히 짚어 줍니다.
- MA(1) PACF (우하): 양수 음수를 오가며 점진적으로 줄어듭니다. cut-off 없음.
진단 패턴이 거울처럼 대칭이라는 점을 주목하세요. AR은 PACF가 끊기고, MA는 ACF가 끊깁니다. 이 비대칭이 두 모형을 구분하는 핵심 단서입니다.
statsmodels로 직접 그릴 때는 한 줄이면 됩니다.
1
2
3
4
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plot_acf(series, lags=20)
plot_pacf(series, lags=20, method='ywm') # Yule-Walker modified
2.2 현실은 그리 깔끔하지 않다
여기까지는 교과서적입니다. 실제 데이터에서는 ACF와 PACF가 둘 다 애매하게 감쇠하거나, 잡음이 많아 패턴이 잘 안 보일 때가 흔합니다. 그래서 실무에서는 ACF/PACF로 후보 차수 몇 개를 추리고 → 각 후보를 적합한 다음 → AIC, BIC 같은 정보 기준(information criterion) 으로 최종 선택합니다.
2.3 AIC와 BIC — 모형 선택의 두 잣대
AIC (Akaike Information Criterion) 와 BIC (Bayesian Information Criterion) 는 둘 다 같은 발상을 따릅니다. “모형이 데이터를 얼마나 잘 설명하는가(가능도)”와 “모형이 얼마나 복잡한가(모수 개수)”를 함께 평가해서, 둘의 균형이 좋은 모형을 고르는 것입니다.6
수식으로는 다음과 같습니다.
\[\begin{aligned} \text{AIC} &= -2 \log L + 2k \\ \text{BIC} &= -2 \log L + k \log n \end{aligned}\]여기서 $\log L$은 적합된 모형의 로그가능도7, $k$는 모수 개수, $n$은 표본 크기입니다. 두 값 모두 작을수록 좋은 모형입니다.
핵심은 두 번째 항입니다. 모수가 많을수록 가능도($\log L$)는 거의 항상 올라가지만(과적합), 두 번째 항이 그 대가를 페널티로 부과합니다. 즉 “모수를 추가해도 그만큼 설명력이 늘지 않으면 채택하지 마라”는 원리입니다.
AIC와 BIC의 차이는 페널티의 강도입니다.
| 기준 | 페널티 항 | 성격 |
|---|---|---|
| AIC | $2k$ | 표본 크기와 무관한 고정 페널티. 더 복잡한 모형을 허용하는 경향 |
| BIC | $k \log n$ | 표본 크기 $n$이 클수록 페널티가 커짐. 더 단순한 모형을 선택하는 경향 |
데이터가 많아질수록 BIC는 AIC보다 더 단순한 모형을 고릅니다. 학술적 입장은 갈리지만, 시계열 예측 실무에서는 보통 AIC를 더 자주 씁니다. BIC가 너무 단순한 모형을 선호해 예측력이 떨어질 수 있다는 우려 때문입니다.8
2.4 auto_arima로 자동 차수 선택
pmdarima 패키지의 auto_arima는 위 원리를 자동화합니다. 일반적인 절차에서는 d, D 같은 차분 차수를 단위근 검정으로 먼저 정하거나 후보로 제한하고, 그 위에서 가능한 p, q, P, Q 조합의 AIC(또는 BIC)를 비교해 모형을 반환합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import numpy as np
import pandas as pd
from pmdarima import auto_arima
# 예시 데이터 (월별 시계열 가정)
# series는 pandas Series 또는 numpy array
# AIC 기준 자동 선택
model_aic = auto_arima(
series,
start_p=0, max_p=5, # AR 차수 후보 0~5
start_q=0, max_q=5, # MA 차수 후보 0~5
d=None, # None이면 ADF 검정으로 자동 결정
seasonal=True,
m=12, # 월별 데이터의 계절 주기
start_P=0, max_P=2,
start_Q=0, max_Q=2,
D=None, # 계절 차분도 자동
information_criterion='aic', # 'aic' 또는 'bic'
stepwise=True, # 빠른 stepwise 탐색
suppress_warnings=True,
trace=True, # 탐색 과정 출력
)
print(model_aic.summary())
# 같은 데이터를 BIC 기준으로도 비교
model_bic = auto_arima(
series, seasonal=True, m=12,
information_criterion='bic',
stepwise=True, suppress_warnings=True,
)
print(f"AIC 기준 선택: {model_aic.order}, seasonal={model_aic.seasonal_order}")
print(f"BIC 기준 선택: {model_bic.order}, seasonal={model_bic.seasonal_order}")
stepwise=True를 권하는 이유: 차수 조합을 모두 격자 탐색하면 시간이 오래 걸리기 때문입니다. Hyndman & Khandakar(2008)가 제안한 stepwise 알고리즘은 후보 모형을 효율적으로 좁혀 가며 거의 같은 결과를 훨씬 빠르게 줍니다.9
유의할 점:
auto_arima는 만능이 아닙니다. AIC/BIC가 최소인 모형이 반드시 예측 성능이 가장 좋은 것도 아니고, 잔차 진단(자기상관, 정규성)을 통과한다는 보장도 없습니다. 자동 선택 후에는 잔차의 ACF/PACF, Ljung-Box 검정 등으로 모형이 데이터를 충분히 설명하는지 별도로 점검해야 합니다.
2.5 탐색 범위와 모수 개수 — 한 단계 더 들어가기
여기까지 따라오시고 나면 자연스럽게 두 가지 의문이 생깁니다.
“AIC/BIC는 정확히 무엇을 탐색하는가? 차분 차수 $d$나 계절 주기 $m$도 같이 비교하나?” “차수가 0이면 그 부분의 모수는 카운트되지 않을 텐데, 페널티 항의 $k$는 어떻게 계산되나?”
두 질문 모두 짚어 둘 가치가 있습니다.
(1) AIC/BIC는 점수일 뿐, 탐색을 직접 하지 않는다
먼저 분명히 해 둘 것이 있습니다. AIC와 BIC는 점수 함수입니다. 모형 하나를 받아서 점수 하나를 돌려주는 것이 전부예요. 차수 조합을 만들고 비교하는 일은 auto_arima 같은 탐색 알고리즘의 책임입니다.
(2) 어떤 차수가 AIC/BIC로 비교되고, 어떤 차수가 그렇지 않은가
auto_arima(seasonal=True, m=12)가 실제로 결정하는 차수들을 정리하면:
| 차수 | 결정 방식 |
|---|---|
| $p, q, P, Q$ | AIC/BIC 격자 탐색 (사용자가 지정한 범위 내) |
| $d, D$ | 단위근 검정 (KPSS, ADF 등) — AIC/BIC 비교 아님 |
| $m$ | 사용자가 도메인 지식으로 직접 지정 |
차분 차수가 AIC/BIC 비교에서 제외되는 이유는 단순합니다. 차분을 다르게 적용한 두 모형은 다른 데이터에 적합된 셈이라 가능도가 직접 비교되지 않습니다. $\Delta y_t$의 가능도와 $\Delta^2 y_t$의 가능도는 서로 다른 데이터셋에 대한 점수라 비교 의미가 없어요. 그래서 auto_arima는 $d$와 $D$를 별도 검정으로 먼저 정하고, 그 값을 고정한 뒤 $p, q, P, Q$만 격자 탐색합니다 (test='kpss', seasonal_test='ocsb' 등의 인자로 검정 종류를 지정할 수 있습니다).
계절 주기 $m$은 탐색 대상이 아닙니다 — 월별 데이터는 12, 일별 주간 패턴은 7처럼 데이터를 보고 사용자가 지정해야 합니다.
(3) 페널티 항의 $k$는 정확히 무엇을 세는가
AIC의 정의를 다시 보면 $\text{AIC} = -2 \log L + 2k$였습니다. 여기서 $k$는 실제로 추정된 자유 모수의 개수입니다. 차수가 0이면 그 부분에 추정할 모수가 없으니 $k$에 들어가지 않습니다.
ARIMA(p, d, q)에서 $k$는 다음으로 계산됩니다.
\[k = p + q + (\text{상수항, 포함하는 경우 1}) + (\text{오차분산 } \sigma^2, 1)\]차수별 예시(상수항 미포함 가정):
| 모형 | 추정되는 모수 | $k$ |
|---|---|---|
| ARIMA(2, 1, 1) | $\phi_1, \phi_2, \theta_1, \sigma^2$ | 4 |
| ARIMA(0, 1, 1) | $\theta_1, \sigma^2$ | 2 |
| ARIMA(1, 1, 0) | $\phi_1, \sigma^2$ | 2 |
| ARIMA(0, 0, 0) | $\sigma^2$ | 1 |
차수가 0인 부분은 페널티에서 빠진다는 사실이 정보 기준의 핵심 메커니즘입니다. 모수가 적은 단순한 모형이 가능도 손해를 페널티 절감으로 만회할 수 있게 해 주는 거지요.
구체적인 비교 예를 들면, 같은 데이터에 ARIMA(2, 1, 1)과 ARIMA(0, 1, 1)을 적합한 결과가 다음과 같다고 합시다.
- ARIMA(2, 1, 1): $\log L = -120$, $k = 4$ → AIC $= 240 + 8 = 248$
- ARIMA(0, 1, 1): $\log L = -123$, $k = 2$ → AIC $= 246 + 4 = 250$
가능도는 ARIMA(2, 1, 1)이 더 높지만(=$\log L$이 덜 음수), 모수가 2개 더 많아서 페널티 4를 더 받습니다. 결국 AIC는 ARIMA(2, 1, 1)이 248로 더 작아 이쪽이 선택됩니다. 만약 가능도 차이가 더 작았다면(예: $\log L_1 = -122$, $\log L_2 = -123$) 페널티가 이겨서 ARIMA(0, 1, 1)이 선택될 것입니다. 이게 “정보 기준이 가능도와 모수 개수 사이의 균형을 잡는다”는 말의 구체적인 작동 방식입니다.
참고:
statsmodels의SARIMAX에서 상수항(intercept)이나 추세항(trend)을 포함하는지에 따라 $k$가 1~2 정도 달라집니다. 같은 차수의 모형이라도 옵션이 다르면 AIC/BIC 값이 살짝 차이 날 수 있어, 다른 라이브러리나 다른 문헌의 값과 비교할 때는 옵션을 맞춰야 합니다.
이번 글에서는 차수 결정을 그 정도까지만 다루고, 차수 $p, q$가 정해졌다고 가정한 상태로 모형을 쌓아 가겠습니다.
3. ARMA — 두 부품 합치기
ARMA(p, q)는 단순히 AR과 MA를 더한 것입니다.
\[y_t = \underbrace{\phi_1 y_{t-1} + \phi_2 y_{t-2} + \cdots + \phi_p y_{t-p}}_{\text{AR(p)}} + \underbrace{\epsilon_t + \theta_1 \epsilon_{t-1} + \cdots + \theta_q \epsilon_{t-q}}_{\text{MA(q)}}\]모수는 $\phi_1, \ldots, \phi_p$ ($p$개)와 $\theta_1, \ldots, \theta_q$ ($q$개)로 총 $p+q$개입니다 (오차 분산 $\sigma^2$ 제외).
ARMA의 강력함은 하나의 시계열에 자기회귀 성분과 이동평균 성분이 동시에 있을 때 둘 다 잡아 준다는 점입니다. AR만 쓰면 MA적 성분이 잔차에 남고, MA만 쓰면 AR적 성분이 남습니다.
다만 ARMA는 약정상 시계열을 가정합니다. 평균과 분산이 시간에 따라 변하지 않아야 한다는 조건입니다. 추세가 있는 시계열, 즉 비정상 시계열에는 그대로 적용할 수 없습니다.
4. ARIMA — 차분으로 비정상을 정상화
비정상 시계열을 어떻게 다룰까요? 이전 글에서 다룬 차분(differencing) 이 답입니다. 차분을 한 번 적용하면 랜덤워크형 확률적 추세를 다루기 쉬워지고, 두 번 적용하면 더 강한 저주파 움직임까지 제거할 수 있습니다. 다만 결정론적 선형 추세라면 차분보다 시간 추세 회귀로 제거하는 방법이 더 적절할 수 있습니다.
ARIMA(p, d, q)는 정확히 이런 모형입니다.
원본 시계열에 $d$번 차분을 적용한 결과를 ARMA(p, q)로 적합한다.
수식으로는 차분 연산자 $\Delta y_t = y_t - y_{t-1}$를 써서:
\[\Delta^d y_t \sim \text{ARMA}(p, q)\]세 모수의 의미는 다음과 같습니다.
- $p$: AR 차수
- $d$: 차분 횟수
- $q$: MA 차수
4.1 d는 어떻게 정하는가
$d$는 통계적 추정이라기보다 진단 기반 결정입니다. 절차는 이렇습니다.
- 원본 시계열에 ADF/KPSS 검정 → 정상이면 $d=0$
- 비정상이면 1차 차분 후 다시 검정 → 정상이면 $d=1$
- 그래도 비정상이면 2차 차분 → $d=2$
실무에서 $d \geq 3$인 경우는 거의 없습니다. Hyndman & Athanasopoulos(2021)도 명시적으로 “거의 항상 $d=0, 1, 2$ 안에서 결정된다”고 지적합니다.10 3차 이상의 차분이 필요하다는 건 시계열에 비정상성 외의 구조적 문제(예: 분산 비균일성, 구조변화)가 있다는 신호일 가능성이 높습니다. 이때는 차분 대신 로그/Box-Cox 변환이나 구조변화 모형을 먼저 검토하는 게 맞습니다.
4.2 정리
ARIMA(p, d, q)는 결국 다음의 조합입니다.
- 차분으로 비정상 시계열을 정상으로 만들고
- AR로 자기회귀 성분을 잡고
- MA로 충격의 단기 영향을 잡는다
5. SARIMA — 계절성까지
월별 매출, 일별 전기 사용량, 시간대별 웹 트래픽 — 현실의 시계열은 대부분 계절성(seasonality) 을 가지고 있습니다. 매년 12월에 매출이 오르고, 매주 월요일에 트래픽이 급등하는 식이지요.
ARIMA만으로는 이런 주기적 패턴을 잡기 어렵습니다. 그래서 등장하는 것이 SARIMA(Seasonal ARIMA) 입니다.
5.1 SARIMA(p, d, q)(P, D, Q, m)
표기가 한 단계 길어졌습니다. 풀어 보면:
- $(p, d, q)$ — 일반(non-seasonal) 부분의 AR, 차분, MA 차수
- $(P, D, Q, m)$ — 계절(seasonal) 부분의 AR, 차분, MA 차수, 그리고 계절 주기 $m$
$m$(계절 주기)이 핵심입니다. 월별 데이터는 $m=12$, 일별이지만 주 단위 패턴이 있다면 $m=7$, 시간별이지만 일 단위 패턴이라면 $m=24$ 식입니다.
5.2 계절 차분이란
일반 차분이 $\Delta y_t = y_t - y_{t-1}$이라면, 계절 차분은 $\Delta_m y_t = y_t - y_{t-m}$입니다. 한 주기 전 같은 시점의 값을 빼는 것입니다. 1년 전 같은 달의 값을 빼면 계절 효과가 사라집니다.
| 변환 | 정의 | 제거하는 성분 |
|---|---|---|
| 1차 차분 | $\Delta y_t = y_t - y_{t-1}$ | 추세 |
| 계절 차분 | $\Delta_m y_t = y_t - y_{t-m}$ | 계절성 |
| 둘 다 | $\Delta \Delta_m y_t$ | 추세 + 계절성 |
추세와 계절성이 모두 있는 시계열은 보통 두 가지 차분을 다 적용합니다.
5.3 시각화
추세와 계절성(주기 12)을 모두 가진 인공 시계열에 각 차분을 단계적으로 적용해 봤습니다.
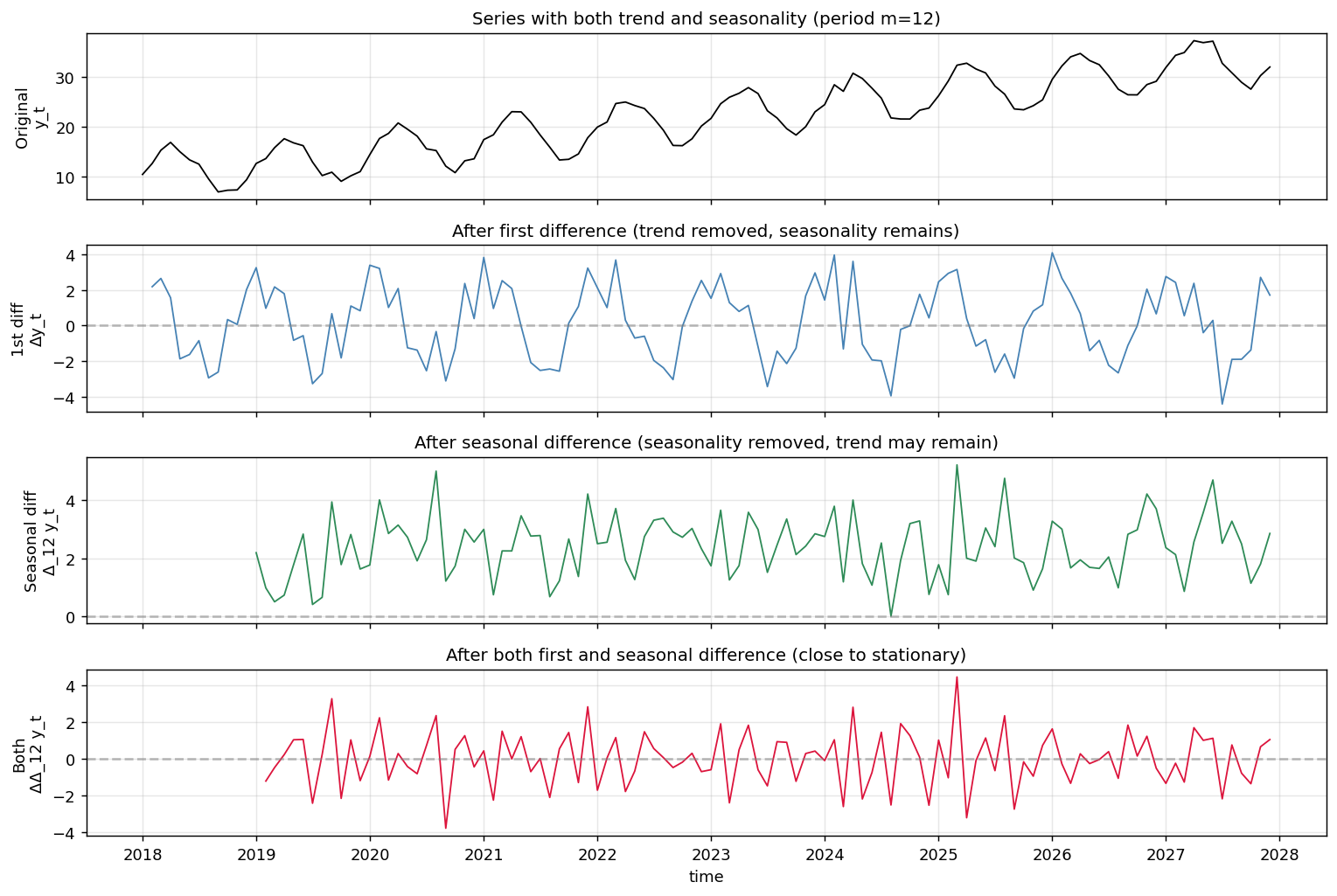
위에서부터:
- 원본: 우상향 추세에 12개월 주기 사인파가 얹혀 있음
- 1차 차분 후: 추세는 사라졌지만 계절성은 그대로
- 계절 차분 후: 계절성은 사라졌지만 추세 흔적이 남음 (값들이 0이 아닌 양수 영역에 모여 있음)
- 둘 다 적용: 0 주변에서 안정적으로 흔들림 — 정상에 가까움
이 마지막 시리즈에 ARMA를 적합하면 SARIMA(p, 1, q)(P, 1, Q, 12) 형태가 됩니다.
5.4 차수가 많아 보이지만
SARIMA(p, d, q)(P, D, Q, m)는 모수 7개로 보이지만, 실제로 $m$은 데이터 특성상 정해지고($m=12$인지 $m=7$인지는 데이터를 보면 압니다), $d$와 $D$는 보통 0이나 1입니다. 핵심적으로 결정해야 하는 것은 $p, q, P, Q$ 네 개입니다.
실무에서는 auto_arima(pmdarima 패키지)나 R의 forecast::auto.arima 같은 자동 차수 선택 도구를 자주 씁니다. AIC/BIC 기반 그리드 탐색을 자동으로 해 줍니다.
6. SARIMAX — 외생변수까지
마지막 글자 X는 eXogenous(외생변수) 의 약자입니다.11 다변량 시계열 모델이 아니라는 점을 분명히 짚고 가야 합니다.
6.1 외생변수란
예측 대상 시계열 $y_t$ 외에, 예측에 도움이 될 만한 다른 변수 $x_t$를 추가로 모델에 넣는 것입니다. 예를 들어:
- 매출($y_t$) 예측에 광고비($x_{1,t}$), 휴일 여부($x_{2,t}$)를 추가
- 전기 사용량($y_t$) 예측에 기온($x_{1,t}$), 요일($x_{2,t}$)을 추가
수식으로는 SARIMA에 외생변수 항이 더해진 형태입니다.
\[y_t = \beta_1 x_{1,t} + \beta_2 x_{2,t} + \cdots + \text{SARIMA 부분}\]statsmodels의 SARIMAX 클래스에서 exog 인자로 외생변수를 넘기면 됩니다.
1
2
3
4
from statsmodels.tsa.statespace.sarimax import SARIMAX
model = SARIMAX(y, exog=X, order=(1,1,1), seasonal_order=(1,1,1,12))
result = model.fit()
6.2 SARIMAX와 다변량 시계열은 무엇이 다른가
여기서 짚고 가야 할 용어 문제가 있습니다. “다변량(multivariate)”이라는 단어가 분야에 따라 두 가지 의미로 쓰이기 때문입니다.
- 머신러닝/일반 회귀 관점: 입력 변수가 여러 개면 다변량. $y_t$를 $x_{1,t}, x_{2,t}, x_{3,t}$로 예측하면 “다변량 입력”으로 부를 수 있습니다.
- 시계열 분야의 표준 용법: 예측 대상이 여러 개여야 다변량. $y_t$ 하나만 예측한다면 입력이 몇 개든 단변량(univariate) 시계열입니다.
이 글에서는 시계열 분야 표준을 따라 후자의 의미로 “다변량”을 씁니다. 그 기준에서 보면 SARIMAX는 단변량 시계열 모형 + 외생변수입니다 — 예측 대상이 $y_t$ 하나이기 때문입니다. 진짜 다변량 시계열 모형, 즉 $y_{1,t}, y_{2,t}, \ldots, y_{k,t}$를 동시에 예측하는 모형은 VAR 같은 별도의 모델입니다.
이 차이를 입력 데이터 관점과 처리 과정 관점으로 풀어 보겠습니다.
(1) 입력 데이터의 역할이 다릅니다
| 구분 | SARIMAX | 다변량 시계열 모형 (예: VAR) |
|---|---|---|
| 예측 대상의 개수 | 하나 ($y_t$) | 여러 개 ($y_{1,t}, \ldots, y_{k,t}$) |
| 입력 시계열 | $y_t$ + 외생변수 $x_t$ | 모든 시계열을 동시에 |
| $x_t$의 역할 | $y_t$를 설명하는 보조 | “보조”가 아니라 동등한 변수 |
| 변수 간 영향 | $x_t \to y_t$ (단방향만) | $y_{1,t} \leftrightarrow y_{2,t}$ (상호) |
핵심은 “방향”입니다. SARIMAX는 외생변수 $x_t$가 $y_t$에 영향을 주지만 그 반대는 모형에 들어가지 않습니다. 반면 VAR은 모든 변수가 서로의 과거에 영향을 받는 양방향 구조입니다.
(2) 미래 예측 시 처리가 다릅니다
이 차이가 실무에서 가장 두드러집니다.
- SARIMAX: 미래 예측을 하려면 외생변수의 미래 값 $x_{t+1}, x_{t+2}, \ldots$ 를 별도로 알고 있어야 합니다. 휴일 여부 같은 결정적 변수는 미리 알 수 있고, 기온 같은 변수는 별도 예측 모형이 필요합니다. 외생변수의 미래를 모르면 SARIMAX는 미래를 예측할 수 없습니다.
- VAR: 모든 변수의 미래를 모형 자체가 함께 예측합니다. 별도 입력이 필요 없습니다. 다만 그 대가로 모수가 훨씬 많아집니다(변수 $k$개에 시차 $p$개면 모수 개수가 $k^2 p$ 규모).
(3) 가정의 비대칭성
SARIMAX는 $x_t$를 조건부 외생변수로 두는 비대칭 가정 위에 서 있습니다. 만약 사실은 $y_t$도 $x_t$에 영향을 주는 피드백 구조라면(예: 매출이 광고비 결정에 다시 영향을 주는 경우) 계수 해석이 어려워지고 예측 안정성도 떨어질 수 있습니다. 이런 상황이라면 VAR, dynamic regression, 인과 모형 등을 함께 고려해야 합니다.
(4) 다변량 시계열 모형의 옵션
여러 시계열을 진정으로 함께 다루려면 다음 모형들이 사용됩니다.
- VAR (Vector AutoRegression): 여러 시계열이 서로의 과거에 영향받는 다변량 자기회귀 모형. 가장 표준적인 출발점.
- VECM (Vector Error Correction Model): 변수들 사이에 공적분(cointegration) 관계가 있는 비정상 다변량 시계열용.
- DFM (Dynamic Factor Model): 많은 시계열이 소수의 공통 요인에 의해 움직인다고 가정하는 모형. 거시경제·금융에서 자주 사용.
이 영역은 행렬대수와 다변량 통계가 본격적으로 들어오는 지점입니다. 최근에는 머신러닝/딥러닝 기반 다변량 시계열 모형(LSTM, Temporal Fusion Transformer 등)도 활발히 사용됩니다. 이건 별도 시리즈로 다루는 게 맞을 것 같습니다.
7. 정리
| 모형 | 식 핵심 | 다루는 것 |
|---|---|---|
| AR(p) | $y_t = \sum \phi_i y_{t-i} + \epsilon_t$ | 자기회귀 |
| MA(q) | $y_t = \epsilon_t + \sum \theta_j \epsilon_{t-j}$ | 충격의 단기 영향 |
| ARMA(p, q) | AR + MA | 둘 다 (정상 시계열) |
| ARIMA(p, d, q) | $\Delta^d y_t \sim \text{ARMA}(p, q)$ | 비정상 시계열 (추세) |
| SARIMA(p,d,q)(P,D,Q,m) | ARIMA + 계절 차분 + 계절 AR/MA | 비정상 + 계절성 |
| SARIMAX | SARIMA + 외생변수 | 위 + 보조 입력 변수 |
다음 포스팅에서는 이 모형들을 실제 데이터에 적용하는 흐름 — 데이터 진단부터 모형 선택, 잔차 진단, 예측까지 — 을 처음부터 끝까지 따라가 보겠습니다.
참고문헌
- Akaike, H. (1974). A new look at the statistical model identification. IEEE Transactions on Automatic Control, 19(6), 716–723.
- Box, G. E. P., Jenkins, G. M., Reinsel, G. C., & Ljung, G. M. (2015). Time Series Analysis: Forecasting and Control (5th ed.). Wiley.
- Breidt, F. J., Davis, R. A., Hsu, N.-J., & Rosenblatt, M. (2006). Pile-up probabilities for the Laplace likelihood estimator of a non-invertible first order moving average. IMS Lecture Notes-Monograph Series, 52, 1–19.
- Brockwell, P. J., & Davis, R. A. (2016). Introduction to Time Series and Forecasting (3rd ed.). Springer.
- Burnham, K. P., & Anderson, D. R. (2002). Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach (2nd ed.). Springer.
- Hamilton, J. D. (1994). Time Series Analysis. Princeton University Press.
- Hyndman, R. J., & Athanasopoulos, G. (2021). Forecasting: Principles and Practice (3rd ed.). OTexts. https://otexts.com/fpp3/
- Hyndman, R. J., & Khandakar, Y. (2008). Automatic Time Series Forecasting: The forecast Package for R. Journal of Statistical Software, 27(3), 1–22.
- Schwarz, G. (1978). Estimating the dimension of a model. The Annals of Statistics, 6(2), 461–464.
AI의 도움을 받아 작성되었으며 최대한 레퍼런스를 밝히려 노력했으나 오류가 있을 수 있으니 정확한 정보를 다시 한번 확인하시기 바랍니다.
백색잡음(white noise)은 평균 0, 분산이 일정한 상수이며, 시점 간 상관이 없는 확률과정입니다. AR/MA 모형의 오차항 가정이며, 이 가정이 깨지면 모형의 통계적 성질이 보장되지 않습니다. ↩︎
자세히 풀면, 가우시안 가능도 함수가 $(\theta, \sigma^2)$와 $(1/\theta, \theta^2 \sigma^2)$에서 정확히 동일한 값을 가지기 때문입니다. 즉 두 모형이 같은 데이터를 같은 확률로 생성합니다. 이 식별 불가능성과 단위근 MA의 통계적 거동(pile-up effect, $1/n$ 수렴)에 대한 자세한 논의는 Breidt, Davis, Hsu, Rosenblatt(2006) “Pile-up probabilities for the Laplace likelihood estimator of a non-invertible first order moving average” 참고. 가역성과 정상성의 거울 대칭에 대한 표준 레퍼런스는 Brockwell & Davis(2016) Ch. 3. ↩︎
PACF의 정확한 정의는 “$y_t$와 $y_{t-k}$ 사이에서 $y_{t-1}, \ldots, y_{t-k+1}$의 선형 영향을 모두 제거한 후의 상관계수”입니다. 계산 방법으로는 Yule-Walker 방정식이나 Durbin 알고리즘을 씁니다. 자세한 수식은 Box, Jenkins, Reinsel & Ljung(2015) Ch. 3 참고. ↩︎
이 표는 Box-Jenkins 식별 절차의 핵심입니다. 자세한 논의와 예시는 Hamilton(1994) Ch. 4 또는 Box et al.(2015) Ch. 6에서 다룹니다. ↩︎
95% 신뢰구간(파란 띠)의 폭은 $\pm 1.96/\sqrt{n}$로 근사 계산되며, 이는 백색잡음 가정 하에서 표본 자기상관계수의 점근분포가 $\mathcal{N}(0, 1/n)$을 따른다는 사실에서 나옵니다. 다만 이는 ACF의 모든 시차에 대한 동시 검정이 아니라 각 시차에 대한 개별 검정 기준이라, 시차가 많아지면 일부 막대가 우연히 띠 밖으로 튀어나올 수 있다는 점은 주의해야 합니다 (다중검정 문제). Bartlett(1946) 공식으로 더 정확한 띠를 그릴 수도 있습니다. ↩︎
AIC는 Akaike(1974) “A new look at the statistical model identification”에서, BIC는 Schwarz(1978) “Estimating the dimension of a model”에서 처음 제안되었습니다. 두 기준의 통계학적 유도와 비교에 대한 표준 레퍼런스는 Burnham & Anderson(2002) Model Selection and Multimodel Inference (2nd ed., Springer)입니다. ↩︎
가능도(likelihood)는 “이 모수 값이 우리가 관찰한 데이터를 얼마나 그럴듯하게 설명하는지”의 점수로, 데이터 $y_1, \ldots, y_n$이 모수 $\boldsymbol{\theta}$ 하에서 나올 확률(밀도)을 $\boldsymbol{\theta}$의 함수로 본 것입니다. 가능도 자체는 매우 작은 수의 곱이라 수치적으로 다루기 어렵기 때문에 보통 로그를 씌운 로그가능도 $\log L = \log L(\boldsymbol{\theta} \mid \text{data})$을 씁니다. 곱이 합으로 바뀌어 계산이 안정되고, 미분(MLE 추정)도 쉬워집니다. 가능도와 MLE에 대한 직관적 정의는 이 시리즈의 이전 글 “데이터 뒤에는 모수가 있다”에서 다뤘습니다. ↩︎
AIC vs BIC 선택은 사용 목적과 표본 크기에 따라 달라집니다. AIC는 점근적으로 예측 오차를 최소화하는 모형을 고르는 경향이 있고, BIC는 표본 크기가 무한대로 갈 때 진짜 모형(true model)을 일치성 있게 선택합니다. 시계열 예측 실무 권고는 Hyndman & Athanasopoulos(2021) Section 9.10 참고. ↩︎
Hyndman, R. J., & Khandakar, Y. (2008). “Automatic Time Series Forecasting: The forecast Package for R.” Journal of Statistical Software, 27(3), 1–22. R의
forecast::auto.arima와 Pythonpmdarima의 핵심 알고리즘이 이 논문에 기반합니다. ↩︎Hyndman, R. J., & Athanasopoulos, G. (2021). Forecasting: Principles and Practice (3rd ed.), Section 9.1. 무료 온라인 교재로 공개되어 있습니다 (otexts.com/fpp3). ↩︎
외생변수(exogenous variable)란 모형 안에서 결정되지 않고 외부에서 주어지는 변수를 의미합니다. 반대 개념은 내생변수(endogenous variable)입니다. SARIMAX의 외생변수는 정확히 말해 “조건부 외생(conditionally exogenous)” 가정 하에 다뤄지며, 자세한 논의는 Hamilton(1994) Ch. 8 참고. ↩︎